Project 2: System Calls
System Calls
- The second project significantly upgraded the PintOS by:
- Enabling child processes to load and execute files.
- Implementing argument passing to child processes.
- Adding system call functionality with robust synchronization.
-
Below, I outlined the objectives, challenges, solutions, and implementations for each component.
Part 1: Executable Loading
Objective
- The primary objective of this section is to reimplement the
process_wait()function to enable a parent process to reliably synchronize with its child process.- Specifically, the parent must be able to wait until its child successfully loads and executes a specified file, or until the child terminates.
Current Problem
- The original
process_wait()function in PintOS was essentially non-functional, serving as a mere placeholder that always returned-1. -
This complete lack of implementation meant that there was no mechanism for a parent process to synchronize with its children.
Click to see the original code
int process_wait (tid_t child_tid UNUSED) { return -1; }
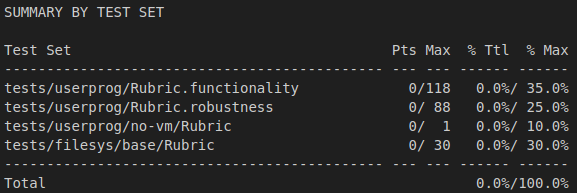
Original Grade
Solution
- To overcome these limitations, the
process_wait()function has been comprehensively redesigned to:- Maintain a Parent-Child Hierarchy:
- A linked list structure within
struct threadis used to maintain a clear hierarchy of child processes for each parent, allowing the parent to track its direct descendants.
- A linked list structure within
- Enable Parent Waiting:
- The parent process can now effectively suspend its execution until a specified child process completes its execution.
- Utilize Semaphores for Synchronization:
- Semaphores are employed as the core synchronization primitive.
- This ensures that the parent is reliably notified and can resume execution only after the child process has exited, or after the child has reported its loading status.
- Maintain a Parent-Child Hierarchy:
Implementation Details
- The following components have been modified or introduced:
thread.hstruct thread- New members are added to
struct threadto support child process management and synchronization:struct list children: A list to hold thestruct list_elem childelemof all child threads spawned by this thread.struct list_elem childelem: A list element used to link a child thread into its parent’schildrenlist.struct semaphore sema_parent: A semaphore used by the parent to wait for the child’s exit status.struct semaphore sema_child: A semaphore used by the child to signal its exit to the parent.int exit_status: An integer to store the exit status of the child process.
- These new members are properly initialized within the
init_thread()function, similar to howdonorswere handled in the previous part.Click to see the refined code
struct thread { /* Owned by thread.c. */ tid_t tid; /* Thread identifier. */ enum thread_status status; /* Thread state. */ char name[16]; /* Name (for debugging purposes). */ uint8_t *stack; /* Saved stack pointer. */ int priority; /* Priority. */ struct list_elem allelem; /* List element for all threads list. */ /* Shared between thread.c and synch.c. */ struct list_elem elem; /* List element. */ int64_t tick_wakeup; /* Tick till wake up */ struct lock *lock_to_wait; /* Address of the lock to wait */ int original_priority; /* Original Priority value */ struct list donors; /* Doners for priority inversion */ struct list_elem donelem; /* List element for donors list */ #ifdef USERPROG /* Owned by userprog/process.c. */ uint32_t *pagedir; /* Page directory. */ struct list children; /* List of child processes */ struct list_elem childelem; /* List element for child processes */ struct semaphore sema_parent; /* Semaphore for waiting parent process*/ struct semaphore sema_child; /* Semaphore for waiting child process*/ int exit_status; /* Exit status for exit() */ #endif /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
- New members are added to
thread.cinit_thread()- This function is updated to initialize the newly added data members for child process tracking and synchronization, specifically
children,sema_parent,sema_child, andexit_status.Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes list_init(&t->donors); #ifdef USERPROG list_init(&t->children); sema_init(&t->sema_parent, 0); sema_init(&t->sema_child, 0); t->exit_status = -1; #endif old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
- This function is updated to initialize the newly added data members for child process tracking and synchronization, specifically
thread_create()- When a new thread (child process) is created, it is now added to the children list of the current (parent) thread, establishing the parent-child relationship.
Click to see the refined code
tid_t thread_create (const char *name, int priority, thread_func *function, void *aux) { struct thread *t; // other codes sf->ebp = 0; #ifdef USERPROG /* push child process to parent */ list_push_back(&thread_current()->children, &t->childelem); #endif // other codes }
- When a new thread (child process) is created, it is now added to the children list of the current (parent) thread, establishing the parent-child relationship.
thread_exit()- Before a thread exits, it signals its parent using
sema_up(&thread_current()->sema_child), notifying the parent that it has terminated. - It then waits on
sema_parentto ensure the parent has retrieved its exit status before fully destroying its resources.Click to see the refined code
void thread_exit (void) { ASSERT (!intr_context ()); #ifdef USERPROG sema_up(&thread_current()->sema_child); process_exit (); sema_down(&thread_current()->sema_parent); #endif /* Remove thread from all threads list, set our status to dying, and schedule another process. That process will destroy us when it calls thread_schedule_tail(). */ intr_disable (); list_remove (&thread_current()->allelem); thread_current ()->status = THREAD_DYING; schedule (); NOT_REACHED (); }
- Before a thread exits, it signals its parent using
process.cprocess_wait()- This function is responsible for the parent process waiting.
- It iterates through the current thread’s
childrenlist to find the child with the matchingchild_tid. - Once found,
- the child is removed from the list, and the parent calls
sema_down(&child_thread->sema_child), effectively blocking until the child signals its exit.
- the child is removed from the list, and the parent calls
- After the child exits,
- the parent retrieves the child’s
exit_statusand then signals the child (which is now in theTHREAD_DYINGstate) viasema_up(&child_thread->sema_parent), allowing the child’s resources to be fully deallocated.
- the parent retrieves the child’s
- If the
child_tiddoes not correspond to a direct child, or if the child has already been waited upon,- it simply returns
-1.
Click to see the refined code
int process_wait (tid_t child_tid) { struct thread *child_thread = NULL, *current_thread = thread_current(); for(struct list_elem *current_element = list_begin(¤t_thread->children), *end_element = list_end(¤t_thread->children); current_element != end_element; current_element = list_next(current_element)) { struct thread *thread_current_element = list_entry(current_element, struct thread, childelem); if (thread_current_element->tid == child_tid) { child_thread = thread_current_element; list_remove(current_element); break; } } if(child_thread == NULL) return -1; sema_down(&child_thread->sema_child); int exit_status = child_thread->exit_status; sema_up(&child_thread->sema_parent); return exit_status; } - it simply returns
Conclusion
- With these modifications, the parent process can now reliably wait for its child’s termination and retrieve its exit status, establishing a crucial synchronization mechanism.
- However, the child’s actual ability to load and execute an executable, along with the passing of arguments, remains to be addressed in subsequent parts of the project.
Part 2: Argument Passing
Objective
- The objective of this section is to enhance the
start_process()function to correctly parse and pass command-line arguments from the parent process to its newly loaded child executable. - This enables user programs to receive and interpret arguments, similar to how command-line applications work in conventional operating systems.
Current Problem
- The original
start_process()function was designed with a fundamental limitation:- it assumed that the
file_nameargument contained only the name of the executable.
- it assumed that the
-
Any additional arguments provided by the user (e.g.,
myprog arg1 arg2) were entirely ignored, making it impossible for user programs to receive and process command-line input.Click to see the original code
static void start_process (void *file_name_) { char *file_name = file_name_; struct intr_frame if_; bool success; /* Initialize interrupt frame and load executable. */ memset (&if_, 0, sizeof if_); if_.gs = if_.fs = if_.es = if_.ds = if_.ss = SEL_UDSEG; if_.cs = SEL_UCSEG; if_.eflags = FLAG_IF | FLAG_MBS; success = load (file_name, &if_.eip, &if_.esp); /* If load failed, quit. */ palloc_free_page (file_name); if (!success) thread_exit (); /* Start the user process by simulating a return from an interrupt, implemented by intr_exit (in threads/intr-stubs.S). Because intr_exit takes all of its arguments on the stack in the form of a `struct intr_frame', we just point the stack pointer (%esp) to our stack frame and jump to it. */ asm volatile ("movl %0, %%esp; jmp intr_exit" : : "g" (&if_) : "memory"); NOT_REACHED (); }
Solution
- To enable robust argument passing,
start_process()has been reimplemented to perform the following key steps:- Argument Parsing:
- The input string containing the executable name and its arguments is parsed to extract individual arguments.
- User Stack Manipulation:
- The parsed arguments are then carefully pushed onto the user stack of the new process.
- This adheres to the 80x86 Calling Convention, which dictates a specific stack layout for command-line arguments
- which is to push the arguments (
argv[i]) from right to left, followed by their starting addresses, the number of arguments (argc), and return address (usually0).
- which is to push the arguments (
- Stack Alignment and Padding:
- It is crucial to ensure that the arguments on the stack are properly aligned to a 4-byte boundary.
- This often involves adding padding bytes to maintain correct memory alignment, which is critical for system stability and performance on x86 architectures.
- Argument Parsing:
Implementation Details
- The following components have been modified or introduced:
syscall.ccollapse_spaces()- A new helper function,
collapse_spaces(), has been introduced.- Its purpose is to normalize the input argument string by replacing multiple consecutive spaces with a single space.
- This ensures consistent parsing and prevents issues caused by variable spacing in the command line.
Click to see the refined code
void collapse_spaces(char *str) { char *source = str, *destination = str; bool in_space = false; while (*source) { if (*source == ' ') { if (in_space == false) { *destination++ = ' '; in_space = true; } } else { *destination++ = *source; in_space = false; } source++; } *destination = '\0'; }
- A new helper function,
start_process()- This function undergoes significant modifications to handle argument parsing and stack setup.
- It first calls
collapse_spaces()on the inputfile_name_. - It then uses
strtok_rto tokenize the string, separating the executable name from its arguments and storing them in a localargvarray.argctracks the number of arguments. - The original
load()function is called with the executable name (argv[0]). - Stack Construction: If
loadis successful, the function proceeds to construct the argument stack frame from bottom to top (highest address to lowest address):- Argument Strings: Each argument string from
argvis copied onto the user stack. The stack pointer (if_.esp) is decremented accordingly. The starting address of each copied argument string is stored inarguments_starting_points. - Padding: Padding bytes are added to ensure that the stack pointer is 4-byte aligned after the argument strings. This is calculated as
(4 - sum_bits % 4) % 4, wheresum_bitsis the total length of the argument strings. - Null
argv[argc]: A null pointer (0) is pushed onto the stack, marking the end of theargvarray for the user program. argvPointers: The addresses stored inarguments_starting_points(pointers to the actual argument strings on the stack) are pushed onto the stack in reverse order (fromargc - 1down to0).argvBase Pointer: The address of the firstargvpointer (arguments_starting_points[0]) is pushed, which will become thechar** argvargument tomain.argc: The count of arguments is pushed.- Fake Return Address: A
0is pushed as a fake return address.
- Argument Strings: Each argument string from
- Finally, an assembly instruction is used to jump to the
intr_exitstub, which will then use the constructedstruct intr_frame(including the modifiedif_.esp) to set up the user process’s initial stack and registers.Click to see the refined code
static void start_process (void *file_name_) { /* Parse the first argument */ collapse_spaces(file_name_); const int MAX_COUNT_ARGUMENT = 32; const int MAX_LENGTH_ARGUMENT = 64; char argv[MAX_COUNT_ARGUMENT][MAX_LENGTH_ARGUMENT]; int argc = 0; char *saveptr, *token = strtok_r(file_name_, " ", &saveptr); while (token != NULL && argc < MAX_COUNT_ARGUMENT) { strlcpy(argv[argc], token, MAX_LENGTH_ARGUMENT); ++argc; token = strtok_r(NULL, " ", &saveptr); } char *file_name = argv[0]; /* Initialize interrupt frame and load executable. */ struct intr_frame if_; bool success; struct thread *current_thread = thread_current(); memset (&if_, 0, sizeof if_); if_.gs = if_.fs = if_.es = if_.ds = if_.ss = SEL_UDSEG; if_.cs = SEL_UCSEG; if_.eflags = FLAG_IF | FLAG_MBS; success = load (file_name, &if_.eip, &if_.esp); /* If load failed, quit. it should be file_name_ not file_name, because file_name_ points to the allocated page */ palloc_free_page (file_name_); if (!success) thread_exit (); /* Push arguments to interrupt frame with the 80x86 calling convention. The registers in interrupt frame will be restored to user stack of the loaded executable */ int sum_bits = 0; int64_t arguments_starting_points[MAX_COUNT_ARGUMENT]; for(int length, current_count = 0; current_count < argc; ++current_count) { length = strlen(argv[current_count]) + 1; if_.esp -= length; // decrement is needed because stack should be moved downward memcpy(if_.esp, argv[current_count], length); arguments_starting_points[current_count] = if_.esp; sum_bits += length; } uint8_t padding_value = (4 - sum_bits % 4) % 4; if(padding_value != 0) { if_.esp -= padding_value; memset(if_.esp, 0, padding_value); // use memset instead of memcpy } if_.esp -= sizeof(char*); memset(if_.esp, 0, sizeof(char*)); for(int current_count = argc - 1; current_count > -1; --current_count) { if_.esp -= sizeof(char*); memcpy(if_.esp, &arguments_starting_points[current_count], sizeof(char*)); // store the actual physical memory address, not the address of local variable } int64_t start_point = if_.esp; if_.esp -= sizeof(char**); memcpy(if_.esp, &start_point, sizeof(char**)); if_.esp -= sizeof(int); memcpy(if_.esp, &argc, sizeof(int)); if_.esp -= sizeof(char*); memset(if_.esp, 0, sizeof(char*)); /* Start the user process by simulating a return from an interrupt, implemented by intr_exit (in threads/intr-stubs.S). Because intr_exit takes all of its arguments on the stack in the form of a `struct intr_frame', we just point the stack pointer (%esp) to our stack frame and jump to it. */ asm volatile ("movl %0, %%esp; jmp intr_exit" : : "g" (&if_) : "memory"); NOT_REACHED (); }
Conclusion
- This comprehensive modification to
start_process()successfully enables child processes to receive and process command-line arguments, significantly enhancing their functionality and interaction capabilities. - While this resolves the argument passing problem, the full utility of these arguments, particularly for executing system calls based on them, still depends on the implementation of a robust system call handler (which will be addressed in Part 4).
Part 3: Synchronization Issues
Objective
- Before proceeding with the implementation of comprehensive system call functionality, it is crucial to address potential race conditions that can arise during concurrent file operations.
- The primary objective here is to ensure the integrity and consistency of the file system by introducing robust synchronization mechanisms.
- This involves implementing a global file system lock (
filesys_lock) and strategically utilizingfile_deny_write()to prevent unauthorized or conflicting modifications to executable files.
- This involves implementing a global file system lock (
Current Problem
- The existing PintOS kernel suffered from a critical vulnerability:
- it lacked a dedicated
filesys_lockto protect shared file system resources.
- it lacked a dedicated
- Furthermore, the
load()function, responsible for loading executables, did not explicitly callfile_deny_write()after a file was loaded.- This oversight meant that a loaded executable could potentially be modified or deleted by another process while it was still being used, leading to unpredictable behavior, crashes, or security vulnerabilities due to concurrent file access.
Click to see the original code
bool load (const char *file_name, void (**eip) (void), void **esp) { struct thread *t = thread_current (); // other codes done: /* We arrive here whether the load is successful or not. */ file_close (file); return success; }
Solution
- To resolve these critical synchronization issues, the following solutions have been implemented:
- Introduction of
filesys_lock:- A global mutex,
filesys_lock, has been introduced. - All operations that access or modify the file system are now protected by this lock, ensuring mutual exclusion and preventing race conditions.
- A global mutex,
- Modified
load()Function:- The
load()function has been updated to:- Acquire
filesys_lockbefore attempting to open and read the executable file. - Call
file_deny_write()immediately after successfully loading an executable.- This prevents other processes from writing to the file while it is still in use by the current process.
- The
file_close()call for the loaded executable has been delayed.- Instead of closing the file immediately after loading, the
struct fileobject representing the loaded executable is now stored in the thread’s structure (current_running_file) and explicitly closed only when the process exits (process_exit()). - This ensures that the deny-write status persists for the entire lifetime of the process using the executable.
- Instead of closing the file immediately after loading, the
filesys_lockis released after the loading process, whether successful or not.
- Acquire
- The
- Enhanced
process_execute():- Before attempting to create a new process,
process_execute()now performs an initial check to verify the existence and accessibility of the specifiedfile_name. - This prevents the creation of threads for non-existent or unopenable files, returning
TID_ERRORearly and avoiding unnecessary resource allocation.
- Before attempting to create a new process,
- Introduction of
Implementation Details
- The following components have been modified or introduced:
syscall.hfilesys_lock- A declaration for the
struct lock filesys_lockhas been added tosyscall.h.- This makes the lock accessible to all parts of the
userprogsubsystem that interact with the file system.
- This makes the lock accessible to all parts of the
- It is explicitly initialized in
syscall_init().Click to see the refined code
#ifndef USERPROG_SYSCALL_H #define USERPROG_SYSCALL_H void syscall_init (void); struct lock filesys_lock; #endif /* userprog/syscall.h */
- A declaration for the
syscall.csyscall_init()- The
syscall_init()function, which is called early in the kernel’s initialization, now includes a call tolock_init(&filesys_lock)to properly initialize the file system lock.Click to see the refined code
void syscall_init (void) { intr_register_int (0x30, 3, INTR_ON, syscall_handler, "syscall"); lock_init(&filesys_lock); }
- The
process.cload()lock_acquire(&filesys_lock)is added beforefilesys_open()to protect the file system during the file opening and loading process.- If the
fileis successfully opened and loaded,file_deny_write(file)is called to prevent modifications to the executable.
- The
file_close(file)call at thedonelabel is removed.- Instead, the file pointer is stored in
t->current_running_filefor later closing.
- Instead, the file pointer is stored in
lock_release(&filesys_lock)is called before returning from the function.Click to see the refined code
bool load (const char *file_name, void (**eip) (void), void **esp) { // other codes /* Open executable file. */ lock_acquire(&filesys_lock); file = filesys_open (file_name); // other codes done: /* We arrive here whether the load is successful or not. */ if(file != NULL) file_deny_write(file); // call this instead of file_close() lock_release(&filesys_lock); t->current_running_file = file; return success; }
process_exit()- When a process exits,
file_close(cur->current_running_file)is now explicitly called. - This releases the deny-write lock on the executable file, allowing it to be modified or deleted once the process is no longer using it.
Click to see the refined code
void process_exit (void) { struct thread *cur = thread_current (); uint32_t *pd; file_close(cur->current_running_file); /* Destroy the current process's page directory and switch back to the kernel-only page directory. */ pd = cur->pagedir; if (pd != NULL) { /* Correct ordering here is crucial. We must set cur->pagedir to NULL before switching page directories, so that a timer interrupt can't switch back to the process page directory. We must activate the base page directory before destroying the process's page directory, or our active page directory will be one that's been freed (and cleared). */ cur->pagedir = NULL; pagedir_activate (NULL); pagedir_destroy (pd); } }
- When a process exits,
process_execute()- Before creating the new thread, ``process_execute
()now acquiresfilesys_lockand attempts tofilesys_open()the executable specified by token (the parsed program name). - If
filesys_open()returnsNULL(indicating the file doesn’t exist or can’t be opened), the lock is released, the allocated page is freed, andTID_ERRORis returned immediately.- This prevents the creation of invalid processes.
- The opened
current_fileis immediately closed after this check, as its purpose was merely to verify existence.Click to see the refined code
tid_t process_execute (const char *file_name) { char *fn_copy; tid_t tid; /* Make a copy of FILE_NAME. Otherwise there's a race between the caller and load(). */ fn_copy = palloc_get_page (0); if (fn_copy == NULL) return TID_ERROR; strlcpy (fn_copy, file_name, PGSIZE); /* Create a new thread to execute FILE_NAME. */ const unsigned MAX_PROCESS_NAME_COUNT = 32; char new_process_name[MAX_PROCESS_NAME_COUNT]; strlcpy(new_process_name, file_name, MAX_PROCESS_NAME_COUNT); char *saveptr, *token = strtok_r(new_process_name, " ", &saveptr); // parse the first argument only to make it as name of the thread lock_acquire(&filesys_lock); struct file* current_file = filesys_open (token); if (current_file == NULL) { lock_release(&filesys_lock); palloc_free_page (fn_copy); return TID_ERROR; } file_close(current_file); lock_release(&filesys_lock); tid = thread_create (token, PRI_DEFAULT, start_process, fn_copy); if (tid == TID_ERROR) palloc_free_page (fn_copy); return tid; }
- Before creating the new thread, ``process_execute
Conclusion
- These crucial synchronization enhancements ensure that file operations are performed safely and consistently, preventing race conditions and maintaining the integrity of the file system.
- By protecting shared resources with
filesys_lockand managing executable writes withfile_deny_write(), PintOS is now far more robust against concurrent access issues. - This foundation is essential for the reliable implementation of system calls, which will be the focus of the next part.
Part 4: System Call Implementation
Objective
- The primary objective of this section is to fundamentally enhance the
syscall_handler()function to provide comprehensive support for a wide range of system calls. - These system calls are essential for user processes to interact with the kernel, enabling operations such as process creation, termination, and various file management tasks.
Current Problem
- The original
syscall_handler()in PintOS was extremely rudimentary.- It merely printed a debugging message
"system call!"and then immediately terminated the calling thread. - This placeholder implementation rendered user programs largely incapable of performing any meaningful interactions with the operating system beyond basic execution and termination.
- It merely printed a debugging message
-
It lacked any mechanism to interpret system call numbers or arguments, let alone dispatch to specific handling routines.
Click to see the original code
static void syscall_handler (struct intr_frame *f UNUSED) { printf ("system call!\n"); thread_exit (); }
Solution
- The
syscall_handler()has been completely reimplemented to transform PintOS into a more functional operating system. - The revised approach includes:
- Argument Validation and Parsing:
- The handler now rigorously validates addresses on the user stack (
f->esp) to ensure they fall within the user’s address space and are mapped. - It then parses the system call number and its corresponding arguments directly from the interrupt frame’s stack:
esp[0]is interpreted as the system call number, which acts as a unique identifier for the requested kernel service.- Subsequent stack locations (
esp[1],esp[2],esp[3], etc.) are treated as the arguments for the specific system call.
- The handler now rigorously validates addresses on the user stack (
- System Call Dispatching:
- Based on the extracted system call number, the handler dispatches control to the appropriate, dedicated system call function
- e.g.,
halt(),exit(),read(),write(),open(), etc.
- e.g.,
- Based on the extracted system call number, the handler dispatches control to the appropriate, dedicated system call function
- Return Value Handling:
- The return value from the system call function is carefully stored in the
eaxregister of the interrupt frame (f->eax), allowing the user process to retrieve the result of its kernel request.
- The return value from the system call function is carefully stored in the
- Comprehensive File Closure on Exit:
- A crucial modification has also been made to
process_exit()to ensure that all open file descriptors belonging to a process are properly closed when that process terminates. - This prevents resource leaks and maintains file system integrity.
- A crucial modification has also been made to
- Argument Validation and Parsing:
Implementation Details
- The following components have been modified or introduced:
thread.h- A macro
FD_TABLE_MAX_SLOThas been defined with a value of32.- This sets the maximum number of file descriptors a single process can simultaneously have open.
struct thread- New members
fd_tableandnext_fdhave been added to manage the file descriptor table.struct file* fd_table[FD_TABLE_MAX_SLOT]:- This array serves as the file descriptor table for each thread, mapping integer file descriptors to their corresponding kernel file objects.
int next_fd:- An integer that tracks the next available (lowest numbered) file descriptor for a given thread, optimizing the allocation of new FDs.
- These new members are properly initialized within
init_thread().Click to see the refined code
#define FD_TABLE_MAX_SLOT 32 struct thread { // other codes struct file* fd_table[FD_TABLE_MAX_SLOT]; /* File Descriptor table*/ int next_fd; /* Empty fd value for next file object */ // other codes };
- New members
- A macro
thread.cinit_thread()- The
init_thread()function has been updated to initialize the new file descriptor related fields.- Specifically,
t->next_fdis set to3(reserving0,1, and2for standard input, output, and error, respectively), and all entries int->fd_tableare initialized toNULL.
Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes list_init(&t->donors); #ifdef USERPROG list_init(&t->children); sema_init(&t->sema_parent, 0); sema_init(&t->sema_child, 0); t->exit_status = -1; t->next_fd = 3; for(unsigned current_index = 0; current_index < FD_TABLE_MAX_SLOT; ++current_index) t->fd_table[current_index] = NULL; t->current_running_file = NULL; #endif old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); } - Specifically,
- The
syscall.cis_valid_address()- A new helper function,
is_valid_address(), has been implemented. - This function performs critical validation by checking two conditions:
- Whether the given
ptris within the user virtual address range (usingis_user_vaddr()).- It’s worth noting that the inclusion of
threads/vaddr.his needed to callis_user_vaddr().
- It’s worth noting that the inclusion of
- Whether the virtual address
ptris actually mapped to a physical page in the current process’s page directory (usingpagedir_get_page()).
- Whether the given
- This function is crucial for preventing segmentation faults and other memory access violations by user programs.
Click to see the refined code
#include "threads/vaddr.h" // other codes bool is_valid_address(void *ptr) { if(ptr != NULL && is_user_vaddr(ptr) == true) { if(pagedir_get_page(thread_current()->pagedir, ptr) != NULL) return true; } return false; }
- A new helper function,
syscall_handler()- This function is the central dispatcher for all system calls.
- It first validates the
f->esp(stack pointer) to prevent access to invalid memory. - A
switchstatement then dispatches to the appropriate system call handler based on the value ofcurrent_esp[0](the system call number). - Arguments for the system calls are retrieved directly from
current_esp[1],current_esp[2],current_esp[3], etc. - The return value from the system call function is assigned to
f->eax, which will be visible to the user program upon return from the interrupt.Click to see the refined code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { case SYS_HALT: halt(); break; case SYS_EXIT: exit(current_esp[1]); break; case SYS_EXEC: f->eax = exec(current_esp[1]); break; case SYS_WAIT: f->eax = wait(current_esp[1]); break; case SYS_CREATE: f->eax = create(current_esp[1], current_esp[2]); break; case SYS_REMOVE: f->eax = remove(current_esp[1]); break; case SYS_OPEN: f->eax = open(current_esp[1]); break; case SYS_FILESIZE: f->eax = filesize(current_esp[1]); break; case SYS_READ: f->eax = read(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_WRITE: f->eax = write(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_SEEK: seek(current_esp[1], current_esp[2]); break; case SYS_TELL: f->eax = tell(current_esp[1]); break; case SYS_CLOSE: close(current_esp[1]); break; } }
- System Call Handlers
halt()- Shuts down PintOS.
Click to see the refined code
void halt(void) { shutdown_power_off(); }
- Shuts down PintOS.
exit()- Terminates the user program with the
exit_status.Click to see the refined code
void exit(int status) { if(status < 0) status = -1; struct thread *current_thread = thread_current(); printf("%s: exit(%d)\n", current_thread->name, status); current_thread->exit_status = status; thread_exit(); }
- Terminates the user program with the
exec()- Runs a new executable with arguments.
Click to see the refined code
int exec(const char *cmd_line) { if(is_valid_address(cmd_line) == false) return -1; const unsigned MAX_PROCESS_NAME_COUNT = 32; char new_process_name[MAX_PROCESS_NAME_COUNT]; strlcpy(new_process_name, cmd_line, MAX_PROCESS_NAME_COUNT); char *saveptr, *token = strtok_r(new_process_name, " ", &saveptr); lock_acquire(&filesys_lock); struct file *temp_file = file_open(token); if(temp_file == NULL) { lock_release(&filesys_lock); return -1; } file_close(temp_file); lock_release(&filesys_lock); return process_execute(cmd_line); }
- Runs a new executable with arguments.
wait()- Waits for a child process and retrieves its
exit_status.Click to see the refined code
int wait(int pid) { return process_wait(pid); }
- Waits for a child process and retrieves its
create()- Creates a file of specified size.
- Returns
trueif successful;falseotherwise.Click to see the refined code
bool create(const char *file, unsigned initial_size) { if(is_valid_address(file) == false) exit(-1); lock_acquire(&filesys_lock); int return_value = filesys_create(file, initial_size); lock_release(&filesys_lock); return return_value; }
remove()- Deletes a file.
- Returns
trueif successful;falseotherwise.Click to see the refined code
bool remove(const char *file) { lock_acquire(&filesys_lock); int return_value = filesys_remove(file); lock_release(&filesys_lock); return return_value; }
open()- Opens a file.
- Returns a
current_fdif successful;-1otherwise.Click to see the refined code
int open(const char *file) { if(is_valid_address(file) == false) exit(-1); struct thread *current_thread = thread_current(); if(current_thread->next_fd == -1) return -1; lock_acquire(&filesys_lock); struct file *current_file = filesys_open(file); if(current_file == NULL) { lock_release(&filesys_lock); return -1; } lock_release(&filesys_lock); current_thread->fd_table[current_thread->next_fd] = current_file; int current_fd = current_thread->next_fd; while(true) { if(current_thread->fd_table[current_thread->next_fd] == NULL) break; ++current_thread->next_fd; if(current_thread->next_fd == FD_TABLE_MAX_SLOT) { current_thread->next_fd = -1; break; } } return current_fd; }
filesize()- Returns the size, in bytes, of the file open as
fd.Click to see the refined code
int filesize(int fd) { if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL) exit(-1); lock_acquire(&filesys_lock); int return_value = file_length(thread_current()->fd_table[fd]); lock_release(&filesys_lock); return return_value; }
- Returns the size, in bytes, of the file open as
read()- Reads size bytes from the file open as
fdinto buffer. - Returns the number of bytes actually read (0 at end of file), or -1 if the file could not be read (due to a condition other than end of file).
fd 0reads from the keyboard usinginput_getc().Click to see the refined code
int read(int fd, void *buffer, unsigned size) { if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL || is_valid_address(buffer) == false || size < 0) exit(-1); if(fd == STDIN_FILENO) return input_getc(); else { lock_acquire(&filesys_lock); int return_value = file_read(thread_current()->fd_table[fd], buffer, size); lock_release(&filesys_lock); return return_value; } }
- Reads size bytes from the file open as
write()- Writes size bytes from buffer to the open file
fd. - Returns the number of bytes actually written, which may be less than size if some bytes could not be written.
Click to see the refined code
int write(int fd, const void *buffer, unsigned size) { if(is_valid_address(buffer) == false || size < 0) exit(-1); if(fd == STDOUT_FILENO) putbuf(buffer, size); else { if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL) exit(-1); lock_acquire(&filesys_lock); int return_value = file_write(thread_current()->fd_table[fd], buffer, size); lock_release(&filesys_lock); return return_value; } return size; }
- Writes size bytes from buffer to the open file
seek()- Changes the next byte to be read or written in open file
fdtoposition, expressed in bytes from the beginning of the file.Click to see the refined code
void seek(int fd, unsigned poisiton) { if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL) exit(-1); lock_acquire(&filesys_lock); file_seek(thread_current()->fd_table[fd], poisiton); lock_release(&filesys_lock); }
- Changes the next byte to be read or written in open file
tell()- Returns the position of the next byte to be read or written in open file
fd, expressed in bytes from the beginning of the file.Click to see the refined code
unsigned tell(int fd) { if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL) exit(-1); lock_acquire(&filesys_lock); int return_value = file_tell(thread_current()->fd_table[fd]); lock_release(&filesys_lock); return return_value; }
- Returns the position of the next byte to be read or written in open file
close()- Closes file descriptor
fd.Click to see the refined code
void close(int fd) { struct thread *current_thread = thread_current(); if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || current_thread->fd_table[fd] == NULL) exit(-1); lock_acquire(&filesys_lock); file_close(current_thread->fd_table[fd]); lock_release(&filesys_lock); current_thread->fd_table[fd] = NULL; current_thread->next_fd = fd; }
- Closes file descriptor
process.cprocess_execute()- To ensure correct behavior for the
oomtest (out of memory),process_execute()now waits for the child process to complete itsload()operation. - It uses
sema_down(&child_thread->sema_child)to block until the child signals its loading status. - The child’s loading success or failure is communicated via
child_thread->exit_status, allowingprocess_execute()to returnTID_ERRORif the child fails to load.
Click to see the refined code
tid_t process_execute (const char *file_name) { // other codes tid = thread_create (token, PRI_DEFAULT, start_process, fn_copy); if (tid == TID_ERROR) palloc_free_page (fn_copy); // respect the result of load() struct thread *child_thread = list_entry(list_back(&thread_current()->children), struct thread, childelem); sema_down(&child_thread->sema_child); if(child_thread->exit_status == TID_ERROR) return TID_ERROR; return tid; }- To ensure correct behavior for the
start_process()- This function, executed by the child thread, now explicitly updates its loading status
(success ? 0 : TID_ERROR)incurrent_thread->exit_statusafter callingload(). - It then signals its parent calling
sema_up(¤t_thread->sema_child), notifying the parent of the loading outcome. - If load fails, it immediately calls
thread_exit().
Click to see the refined code
static void start_process (void *file_name_) { // other codes success = load (file_name, &if_.eip, &if_.esp); /* If load failed, quit. it should be file_name_ not file_name, because file_name_ points to the allocated page */ palloc_free_page (file_name_); // Update loading status to parent thread current_thread->exit_status = success ? 0 : TID_ERROR; sema_up(¤t_thread->sema_child); if (!success) thread_exit(); // other codes }- This function, executed by the child thread, now explicitly updates its loading status
process_exit()- This function has been significantly expanded to perform comprehensive resource cleanup upon process termination:
- Donors List Cleanup:
- It iterates through and removes all remaining thread objects from the
donorslist, ensuring proper deallocation and preventing memory leaks.
- It iterates through and removes all remaining thread objects from the
- Child Process Waiting:
- It iterates through its
childrenlist and callsprocess_wait()for each remaining child. - This ensures that the parent properly clears all its children before exiting, preventing orphaned processes.
- It iterates through its
- File Descriptor Table Cleanup:
- It iterates through the
fd_tableand callsfile_close()for every openstruct file*object, explicitly closing all files opened by the process.
- It iterates through the
- It also explicitly closes the
current_running_file(the executable itself) as discussed in Part 3.
- Donors List Cleanup:
filesys_lockis acquired before closing files and released after all file-related cleanup is done, ensuring atomicity of file system operations during exit.Click to see the refined code
void process_exit (void) { struct thread *cur = thread_current (); uint32_t *pd; for(struct list_elem *current_element = list_begin(&cur->donors), *end_element = list_end(&cur->donors), *next_element; current_element != end_element;) { next_element = list_next(current_element); struct thread *thread_current_element = list_entry(current_element, struct thread, donelem); list_remove(current_element); current_element = next_element; } for(struct list_elem *current_element = list_begin(&cur->children), *end_element = list_end(&cur->children), *next_element; current_element != end_element;) { next_element = list_next(current_element); struct thread *thread_current_element = list_entry(current_element, struct thread, childelem); process_wait(thread_current_element->tid); current_element = next_element; } if(lock_held_by_current_thread(&filesys_lock) == false) lock_acquire(&filesys_lock); /* deallocate opened file objects */ for(--cur->next_fd; cur->next_fd > -1; --cur->next_fd) file_close(cur->fd_table[cur->next_fd]); file_close(cur->current_running_file); /* Destroy the current process's page directory and switch back to the kernel-only page directory. */ pd = cur->pagedir; if (pd != NULL) { /* Correct ordering here is crucial. We must set cur->pagedir to NULL before switching page directories, so that a timer interrupt can't switch back to the process page directory. We must activate the base page directory before destroying the process's page directory, or our active page directory will be one that's been freed (and cleared). */ cur->pagedir = NULL; pagedir_activate (NULL); pagedir_destroy (pd); } lock_release(&filesys_lock); }
- This function has been significantly expanded to perform comprehensive resource cleanup upon process termination:
exception.c- It’s worth noting that this modification is not related to the OS feature but is necessary to pass the tests.
kill()- By default, when a critical error occurs, PintOS calls
kill()to panic the system. - However, for now,
kill()simply callsexit(-1)instead of triggering a system panic.Click to see the refined code
static void kill (struct intr_frame *f) { /* This interrupt is one (probably) caused by a user process. For example, the process might have tried to access unmapped virtual memory (a page fault). For now, we simply kill the user process. Later, we'll want to handle page faults in the kernel. Real Unix-like operating systems pass most exceptions back to the process via signals, but we don't implement them. */ /* The interrupt frame's code segment value tells us where the exception originated. */ /* switch (f->cs) { case SEL_UCSEG: // User's code segment, so it's a user exception, as we // expected. Kill the user process. printf ("%s: dying due to interrupt %#04x (%s).\n", thread_name (), f->vec_no, intr_name (f->vec_no)); intr_dump_frame (f); thread_exit (); case SEL_KCSEG: // Kernel's code segment, which indicates a kernel bug. // Kernel code shouldn't throw exceptions. (Page faults // may cause kernel exceptions--but they shouldn't arrive // here.) Panic the kernel to make the point. intr_dump_frame (f); PANIC ("Kernel bug - unexpected interrupt in kernel"); default: // Some other code segment? Shouldn't happen. Panic the kernel. printf ("Interrupt %#04x (%s) in unknown segment %04x\n", f->vec_no, intr_name (f->vec_no), f->cs); thread_exit (); } */ exit(-1); }
- By default, when a critical error occurs, PintOS calls
page_fault()- Similarly, the
printf()statement has been commented out to pass the tests.Click to see the refined code
static void page_fault (struct intr_frame *f) { // other codes write = (f->error_code & PF_W) != 0; user = (f->error_code & PF_U) != 0; /* To implement virtual memory, delete the rest of the function body, and replace it with code that brings in the page to which fault_addr refers. */ /*printf ("Page fault at %p: %s error %s page in %s context.\n", fault_addr, not_present ? "not present" : "rights violation", write ? "writing" : "reading", user ? "user" : "kernel"); */ kill (f); }
- Similarly, the
exception_print_stats()- Likewise, the
printf()statement has been commented out to pass the tests.Click to see the refined code
void exception_print_stats (void) { //printf ("Exception: %lld page faults\n", page_fault_cnt); ; }
- Likewise, the
Conclusion
- PintOS now supports a robust and functional set of system calls, enabling user programs to perform complex operations like process management, file creation, reading, writing, and various other interactions with the kernel.
- These implementations, coupled with proper argument validation and synchronization, significantly enhance the capabilities and stability of the operating system, allowing for the execution of more sophisticated user applications.
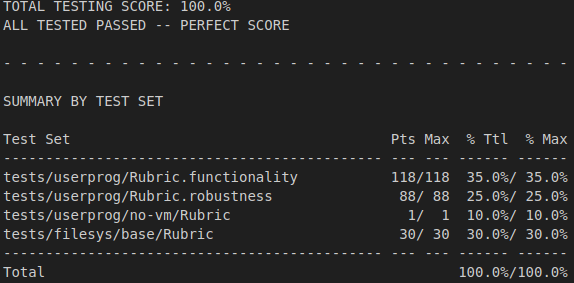
Improved Grade
Final Thoughts
- These enhancements fundamentally transformed PintOS into a significantly more capable and robust operating system by:
- Establishing multitasking through revised process management.
- Enabling command-line input.
- Ensuring file system integrity with robust synchronization mechanisms and a comprehensive suite of system calls.
- This second project significantly expanded PintOS’s features, optimizing resource utilization and thread coordination, bringing it closer to a fully functional operating system environment.
Leave a comment