Project 3: Memory
Memory
- The third project significantly improves PintOS’s memory management by:
- Implementing a supplemental page table for each process.
- Introducing demand paging to effectively handle page faults and support dynamic stack growth.
- Adding memory mapping features to optimize process memory access.
-
Below, I outlined the objectives, challenges, solutions, and implementations for each component.
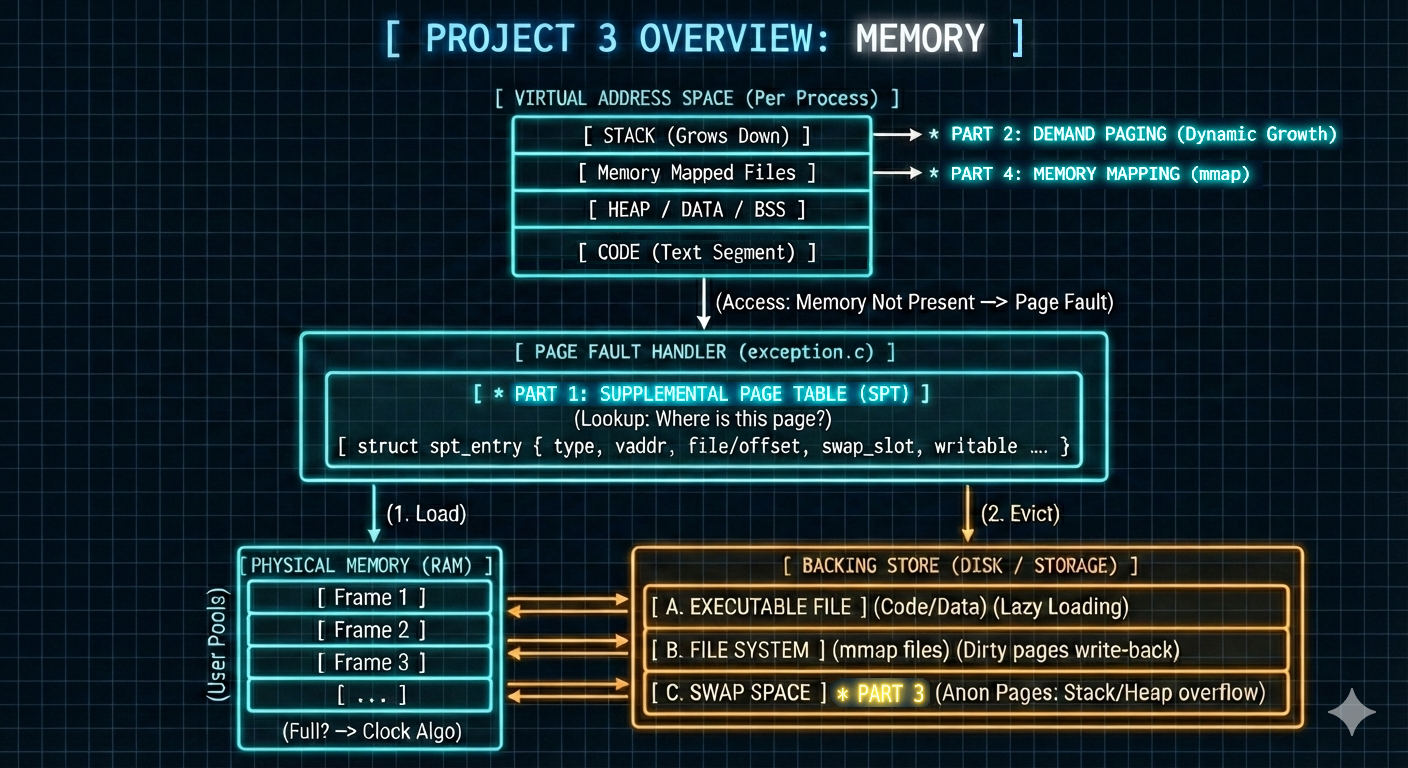
Part 1: Supplemantal Page Table
Objective
- The primary goal of this initial phase is to implement a supplemental page table (SPT) for each process in PintOS.
- This fundamental change is crucial for enabling demand paging, a memory management technique where physical memory pages are allocated only when they are genuinely accessed by a process, rather than being allocated speculatively at process startup.
- This approach aims to significantly optimize memory utilization and improve system scalability.
Current Problem
- The existing
load_segment()function was responsible for loading executable segments. - A key inefficiency in this original implementation was its eager allocation strategy:
- it would allocate all necessary physical pages for each segment at the moment the process was loaded, irrespective of whether those pages would be immediately used.
-
This pre-allocation could lead to substantial and often unnecessary consumption of physical memory, especially for large programs where only a fraction of code or data segment might be actively used at any given time.
Click to see the original code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT (pg_ofs (upage) == 0); ASSERT (ofs % PGSIZE == 0); file_seek (file, ofs); while (read_bytes > 0 || zero_bytes > 0) { /* Calculate how to fill this page. We will read PAGE_READ_BYTES bytes from FILE and zero the final PAGE_ZERO_BYTES bytes. */ size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; /* Get a page of memory. */ uint8_t *kpage = palloc_get_page (PAL_USER); if (kpage == NULL) return false; /* Load this page. */ if (file_read (file, kpage, page_read_bytes) != (int) page_read_bytes) { palloc_free_page (kpage); return false; } memset (kpage + page_read_bytes, 0, page_zero_bytes); /* Add the page to the process's address space. */ if (!install_page (upage, kpage, writable)) { palloc_free_page (kpage); return false; } /* Advance. */ read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; upage += PGSIZE; } return true; }
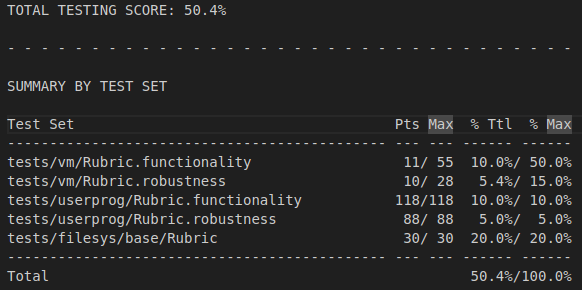
Original Grade
Solution
- My solution involved a fundamental shift in how
load_segment()operates. - Instead of directly requesting and mapping physical memory pages, the reimplemented
load_segment()now populates the newly introduced supplemental page table with entries (struct spt_entry).- These entries serve as placeholders or descriptors, containing all the metadata required to load a physical page later, specifically when that page is actually accessed by the process.
- This deferred allocation strategy dramatically reduces the initial memory footprint of a process.
- To facilitate this, I designed and implemented
struct spt_entry.- This structure is carefully crafted to encapsulate all the necessary information for a virtual page.
-
These
spt_entryinstances form the backbone of the supplemental page table, providing the necessary context for on-demand page loading.
Implementation Details
- The following components have been modified or introduced:
page.hstruct spt_entrypage.hnow includes the definition forstruct spt_entry.- This new structure captures comprehensive information about a virtual page, including
- its type
SPT_BINfor code segmentSPT_ANONfor stack, heap segments, or other typesSPT_FILEformemory-mapped files
- a flag for stack pages (
is_stack), - the virtual address (
vaddr), - the amount of zero-padding (
zero_bytes), - and critical file-related metadata (
file,read_bytes,offset,writable).
- its type
- It also contains a
list_elemto allow its inclusion in astruct listobject which is the SPT.Click to see the refined code
enum page_type { SPT_BIN, /* code segment */ SPT_ANON, /* stack, heap or anonymous */ SPT_FILE /* file-backed page */ }; /* spt_entry for spt in each thread */ struct spt_entry { enum page_type type; // type of page bool is_stack; // flag for stack growth void *vaddr; // virtual page int zero_bytes; // padding info // these are necessary to load the actual file from disk struct file *file; int read_bytes, offset; bool writable; struct list_elem sptelem; // List element for page table };
thread.hstruct thread- A new data member
supplemental_page_tablehas been added tostruct thread.- This member is a
struct listthat will hold all thespt_entryinstances for a given thread, effectively forming its process-specific supplemental page table.
- This member is a
- Additionally,
struct threadnow includes other two data members:current_stack_top: to track the dynamically changing top of the stack for stack growth purposes.- It is initialized in
setup_stack()
- It is initialized in
initial_code_segment: to store the base virtual address of the executable’s code segment, which is useful for validating memory access boundaries.- It is initialized in
start_process().
- It is initialized in
Click to see the refined code
struct thread { // other codes struct list supplemental_page_table; /* supplemental page table */ void *current_stack_top; /* current stack top */ void *initial_code_segment; /* address of code segment */ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
- A new data member
process.cstart_process()- It has been modified to initialize the
supplemental_page_tablelist for the current thread. - It also sets
initial_code_segmenttoNULLbefore any segments are loaded. - This ensures a clean state for the new process’s virtual memory management.
Click to see the refined code
static void start_process (void *file_name_) { // other codes /* Initialize interrupt frame and load executable. */ struct intr_frame if_; bool success; /* Initialize the set of spt_entries */ struct thread *current_thread = thread_current(); list_init(¤t_thread->supplemental_page_table); current_thread->initial_code_segment = NULL; // other codes }
- It has been modified to initialize the
process_exit()- To prevent memory leaks and ensure proper resource cleanup,
process_exit()has been enhanced. - It iterates through the thread’s
supplemental_page_table.- For each
spt_entry, it deallocates the memory associated with the entry itself (usingfree()).
- For each
- This effectively tears down the supplemental page table when a process terminates.
Click to see the refined code
void process_exit (void) { file_close(cur->current_running_file); /* deallocate supplemental page table */ for(struct list_elem *current_element = list_begin(&cur->supplemental_page_table), *end_element = list_end(&cur->supplemental_page_table), *next_element ; current_element != end_element;) { struct spt_entry *target_entry = list_entry(current_element, struct spt_entry, sptelem); next_element = list_next(current_element); list_remove(current_element); free(target_entry); current_element = next_element; } // other code }
- To prevent memory leaks and ensure proper resource cleanup,
load_segment()- This function represents the most significant change in allocation strategy.
- The revised
load_segment()no longer callspalloc_get_page()orinstall_page()directly.- Instead, for each page-sized chunk of the segment, it dynamically allocates a new
spt_entry.
- Instead, for each page-sized chunk of the segment, it dynamically allocates a new
- It populates this entry with the necessary details (virtual address, file information, writability).
- It then adds this
spt_entryto the current thread’ssupplemental_page_table.
- It then adds this
- It also sets the
initial_code_segmentfor the thread if it is the first code segment being processed.Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT (pg_ofs (upage) == 0); ASSERT (ofs % PGSIZE == 0); file_seek (file, ofs); struct thread *current_thread = thread_current(); while (read_bytes > 0 || zero_bytes > 0) { /* Calculate how to fill this page. We will read PAGE_READ_BYTES bytes from FILE and zero the final PAGE_ZERO_BYTES bytes. */ size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; struct spt_entry *new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) return false; new_entry->type = SPT_BIN; new_entry->is_stack = false; new_entry->vaddr = upage; if (current_thread->initial_code_segment == NULL) current_thread->initial_code_segment = upage; new_entry->zero_bytes = page_zero_bytes; new_entry->file = file; new_entry->read_bytes = page_read_bytes; new_entry->offset = ofs; new_entry->writable = writable; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); /* Advance. */ read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; upage += PGSIZE; ofs += PGSIZE; } return true; }
Conclusion
- These modifications successfully lay the groundwork for demand paging.
- They introduce the supplemental page table and fundamentally alter how program segments are loaded.
- By deferring physical page allocations, this implementation significantly reduces the initial memory usage per process.
- However, its ability to handle the page fault remains to be addressed in subsequent parts of the project.
Part 2: Demand Paging
Objective
- The core objective of this part focuses on implementing demand paging within PintOS.
- This mechanism ensures that physical memory pages are allocated only when a process attempts to access them.
- A crucial benefit of demand paging is its enablement of dynamic stack growth.
- This allows the stack to expand automatically as needed, enhancing memory efficiency and flexibility.
Current Problem
- The existing
page_fault()function simply calledkill()to terminate the process when a page fault occurs. -
This design prevents any form of dynamic memory allocation, efficient memory management, or flexible stack usage.
Click to see the original code
static void page_fault (struct intr_frame *f) { bool not_present; /* True: not-present page, false: writing r/o page. */ bool write; /* True: access was write, false: access was read. */ bool user; /* True: access by user, false: access by kernel. */ void *fault_addr; /* Fault address. */ /* Obtain faulting address, the virtual address that was accessed to cause the fault. It may point to code or to data. It is not necessarily the address of the instruction that caused the fault (that's f->eip). See [IA32-v2a] "MOV--Move to/from Control Registers" and [IA32-v3a] 5.15 "Interrupt 14--Page Fault Exception (#PF)". */ asm ("movl %%cr2, %0" : "=r" (fault_addr)); /* Turn interrupts back on (they were only off so that we could be assured of reading CR2 before it changed). */ intr_enable (); /* Count page faults. */ page_fault_cnt++; /* Determine cause. */ not_present = (f->error_code & PF_P) == 0; write = (f->error_code & PF_W) != 0; user = (f->error_code & PF_U) != 0; kill (f); }
Solution
- To handle page faults and support stack growth, I’ve made the following key changes:
- Reimplemented
setup_stack():- This function now initializes the
current_stack_topfor the current thread and sets up the initial stack page in the supplemental page table (spt_entry). - This
spt_entryis crucial for managing the stack growth.
- This function now initializes the
- Introduced
handle_page_fault():- This new function is dedicated to resolving page faults.
- It allocates the required physical page based on the information in the
spt_entryand loads data from disk if necessary. - For now, if memory allocation fails, the process terminates, as page swapping will be addressed in a later part.
- Revised
page_fault():- Instead of terminating the process immediately when a page fault occurs,
page_fault()now callshandle_page_fault()to resolve the fault.
- It also incorporates logic for stack growth, allowing the stack to expand up to
8MB.- If the fault address is within
32 bytesof the stack pointer (f->esp),- the stack growth is permitted.
- If the fault address is invalid, outside the allowed range, or exceeds the maximum stack size,
- the thread is terminated.
- If the fault address is within
- Instead of terminating the process immediately when a page fault occurs,
- Reimplemented
Implementation Details
- The following components have been modified or introduced:
process.csetup_stack()- It Initializes
current_stack_topfor the current thread. - It also creates
spt_entryfor the initial stack page within the thread’s supplemental page table.Click to see the refined code
static bool setup_stack (void **esp) { uint8_t *kpage; bool success = false; struct thread *current_thread = thread_current(); current_thread->current_stack_top = ((uint8_t *) PHYS_BASE) - PGSIZE; kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage != NULL) { success = install_page (current_thread->current_stack_top, kpage, true); if (success) *esp = PHYS_BASE; else palloc_free_page (kpage); } // update supplemental page table struct spt_entry *new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) return false; new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); return success; }
- It Initializes
install_page()- I revised
install_page()by removing itsstaticmodifier.- This makes the function accessible from
page.c, where it needs to be called, even though it’s defined inprocess.c.
Click to see the refined code
bool install_page (void *upage, void *kpage, bool writable) { struct thread *t = thread_current (); /* Verify that there's not already a page at that virtual address, then map our page there. */ return (pagedir_get_page (t->pagedir, upage) == NULL && pagedir_set_page (t->pagedir, upage, kpage, writable)); } - This makes the function accessible from
- I revised
page.chandle_page_fault()- This newly created function orchestrates the actual page loading process.
- It attempts to acquire a new physical page.
- If successful, it checks the page’s type (binary segment, anonymous, or file-backed) from its corresponding
spt_entry.- For file-backed pages,
- it reads data from the disk, ensuring proper file system synchronization by acquiring and releasing a
filesys_lock.
- it reads data from the disk, ensuring proper file system synchronization by acquiring and releasing a
- For other types,
- it just proceeds with the newly allocated page.
- Finally, it maps the allocated physical page to the process’s virtual address using
install_page().
- For file-backed pages,
- A crucial point here is that if memory allocation fails, the function currently returns an error, leading to process termination.
- In order to fix this, page swapping is needed.
- This feature will be implement in the next part.
Click to see the refined code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage == NULL) { // if there's no space, terminate the process for now // page swap is needed return false; } // load the data from disk bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); if(target_spt_entry->type != SPT_ANON) { // if the page is not stack nor heap, then read from the disk if(file_read_at(target_spt_entry->file, kpage, target_spt_entry->read_bytes, target_spt_entry->offset) != target_spt_entry->read_bytes) { palloc_free_page (kpage); lock_release(&filesys_lock); return false; } } else { // if the page is stack or heap, then read from swap space if needed // but skip this for now ; } if(is_lock_already_owned == false) lock_release(&filesys_lock); // update page table if (!install_page (target_spt_entry->vaddr, kpage, target_spt_entry->writable)) { palloc_free_page (kpage); return false; } return true; }
exception.cpage_fault()- This revised interrupt handler now performs initial validation checks on the faulting address, terminating the process for genuinely invalid memory accesses.
- e.g., kernel address space access from user mode, or attempts to access memory outside the process’s legitimate virtual address range.
- It then searches the thread’s supplemental page table for an entry corresponding to the faulting address.
- If a match is found, it calls
handle_page_fault()to load the page instead ofkill().
- If a match is found, it calls
- If no existing
spt_entryis found,page_fault()then checks if the access is a legitimate attempt to extend the stack.- It considers the distance between the faulting address and the current stack pointer (
f->esp).- It’s worth noting that a margin of up to
32 bytesis allowed, as the pusha test pushes32 bytesto the stack. - It also verifies that the stack would not exceed a predefined
MAX_STACK_SIZE.
- It’s worth noting that a margin of up to
- If these conditions are met, it dynamically creates new anonymous page entries in the supplemental page table, expanding the stack downwards as needed, and resolves these new page faults through
handle_page_fault().
- It considers the distance between the faulting address and the current stack pointer (
- Any page fault that doesn’t fit these valid scenarios leads to process termination by calling
exit(-1).Click to see the refined code
#define MAX_STACK_SIZE (8 * 1024 * 1024) // 8MB // other codes static void page_fault (struct intr_frame *f) { // other codes user = (f->error_code & PF_U) != 0; struct thread *current_thread = thread_current(); // Check if the page fault is due to an access violation or invalid memory reference. // If the address is not a valid user virtual address or falls outside the allowed range, // the process is terminated. if(not_present == false || is_user_vaddr(fault_addr) == false || fault_addr < current_thread->initial_code_segment || fault_addr >= PHYS_BASE) exit(-1); // handle page demanding struct spt_entry *target_spt_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table), *end_element = list_end(¤t_thread->supplemental_page_table); current_element != end_element; current_element = list_next(current_element)) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } // handle stack growth // check whether the current attempt is valid for stack growth by comparing the difference between f->esp and fault_addr to 32 bytes. // 32 bytes are chosen due to the pusha test, which pushes 32 bytes. // if the distance is farther than this, terminate the process. // limit the maximum stack growth to MAX_STACK_SIZE (8MB). if(f->esp - fault_addr <= 32 && PHYS_BASE - fault_addr <= MAX_STACK_SIZE) { struct spt_entry *new_entry = NULL; do { // prepare for next stack current_thread->current_stack_top -= PGSIZE; new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) exit(-1); new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; new_entry->slot_index = -1; new_entry->is_immortal = false; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); } while(current_thread->current_stack_top > fault_addr); if(handle_page_fault(new_entry)) return; } exit(-1); }
- This revised interrupt handler now performs initial validation checks on the faulting address, terminating the process for genuinely invalid memory accesses.
Conclusion
- PintOS now features foundational demand paging with dynamic stack growth, improving memory efficiency.
- However, it still assumes sufficient physical memory.
- Without a page swapping mechanism to move less-used pages to disk when memory is exhausted, processes will terminate.
- The next step is to implement page swapping to prevent crashes under memory pressure and allow more processes than available RAM.
Part 3: Page Swap
Objective
- The objective of this section focuses on implementing page swapping in PintOS.
- This capability is essential for:
- Enabling the operating system to manage memory effectively when physical RAM becomes scarce.
- Preventing process termination due to memory exhaustion.
Current Problem
- The current
handle_page_fault()function, while capable of demand paging, would still terminate a process if it failed to allocate a new physical page. -
This abrupt termination occurs when the system ran out of available physical memory, indicating a critical gap in memory management for robust operation under high memory pressure.
Click to see the original code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage == NULL) { // if there's no space, terminate the process for now // page swap is needed return false; } // other codes }
Solution
- My solution addresses the memory exhaustion problem by introducing a page swapping mechanism:
- Revised
handle_page_fault():- This function has been enhanced to intelligently respond to physical memory allocation failures.
- Instead of immediately terminating the process, it now attempts to free up memory by calling
evict_page().
evict_page()Implementation:- This new function is responsible for selecting a victim page from physical memory, writing its contents to swap space if modified, and then freeing its physical frame.
- Victim Page Selection:
- To choose which page to evict,
evict_page()relies onpick_victim_page(). - This function implements the Clock Algorithm, a commonly used page replacement policy.
- The Clock Algorithm efficiently approximates a Least Recently Used (LRU) policy by checking the accessed bit associated with each page.
- If the bit is set, it’s cleared, and the “clock hand” advances.
- If the bit is clear, that page is selected as the victim.
- The Clock Algorithm efficiently approximates a Least Recently Used (LRU) policy by checking the accessed bit associated with each page.
- To choose which page to evict,
- Global Swap Space Management:
- To support page swapping, a dedicated swap space has been established.
- This swap space is designed to be global, meaning it’s shared across all processes.
- I achieved this by having the initial
mainthread create and manage a single, global bitmap representing available swap slots. - This bitmap is then shared and accessed by all subsequent child processes.
- I achieved this by having the initial
is_immortalFlag:- A crucial addition to the
spt_entrystructure is theis_immortalflag. - This flag prevents critical pages from being swapped out.
- This is necessary because the initial stack page must remain in memory to ensure the messages are printed correctly in test files.
- A crucial addition to the
- Revised
Implementation Details
- The following components have been modified or introduced:
thread.hstruct thread- The
struct threadnow includesswap_slots, a pointer to a boolean array representing the global swap space.- The size of this array is defined by
SWAP_SIZE.
- The size of this array is defined by
- It also contains
current_clock_index, an integer that tracks the “hand” of the clock algorithm, used to efficiently find victim pages.- This index is initialized to
0ininit_thread().
Click to see the refined code
#define SWAP_SIZE 1024 struct thread { // other code void *initial_code_segment; /* address of code segment */ bool *swap_slots; /* swap slot */ int current_clock_index; /* current index of page for clock algorithm*/ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ }; - This index is initialized to
- The
thread.cglobal_swap_slots- A boolean array,
global_swap_slots, has been introduced for global accessibility by the main thread and its child threads, serving as the central record for allocated swap sectors.Click to see the refined code
/* Global Swap Slots */ bool global_swap_slots[SWAP_SIZE];
- A boolean array,
thread_init()thread_init()assignsinitial_thread->swap_slotsof themainthread toglobal_swap_slots.Click to see the refined code
void thread_init (void) { // other codes initial_thread->tid = allocate_tid (); /* Set up swap slot */ initial_thread->swap_slots = global_swap_slots; }
init_thread()init_thread()ensures that all child processes also point theirswap_slotsto the sameglobal_swap_slotsarray, thereby guaranteeing that all threads share and manage the same global swap space.- It also initializes each new thread’s
current_clock_indexto0.Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_running_file = NULL; #endif /* child shares the swap slot */ t->swap_slots = global_swap_slots; t->current_clock_index = 0; old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
page.hstruct spt_entry- The
struct spt_entryhas been augmented with two new fields:slot_index:- It stores the index in the swap space where the page’s contents are, or will be, stored.
- It’s initialized to
-1to indicate that a page is not currently in swap.
is_immortal:- It is a boolean flag to protect critical pages from being evicted.
is_immortalshould betrueif the page is:- the initial stack page,
- one of first two pages of the data segment,
- the page belonging to the code segment,
- or the first page of file-backed pages.
- Currently,
load_segment(),page_fault(), andsetup_stack()are responsible for initializing these fields.
Click to see the refined code
struct spt_entry { // other codes bool writable; int slot_index; // needed to check whether it's related to swap space or not bool is_immortal; // needed for page swap struct list_elem sptelem; // List element for page table };- The
page.c- Functions for Swap Space
- Four custom utility functions have been introduced for using the swap space.
- It’s important to note that
block_read()andblock_write()operate based onBLOCK_SECTOR_SIZE(512 bytes), notPGSIZE(4096 bytes).- As a result, 8 block operations (
PGSIZE / BLOCK_SECTOR_SIZE = 8) are required to handle a single page.
Click to see the refined code
/* Returns the available slot index of swap_slots table */ int allocate_swap_index(void) { struct thread* current_thread = thread_current(); // The trick here is that swap_slots is incremented singly, // but when the current_slot is returned, it should be multiplied by // PGSIZE / BLOCK_SECTOR_SIZE, because one page holds 8 sectors. for (int current_slot = 0; current_slot < SWAP_SIZE; ++current_slot) { if (current_thread->swap_slots[current_slot] == false) { current_thread->swap_slots[current_slot] = true; return current_slot; } } return -1; // No free slot available } /* Frees the given slot_index of swap_slots table */ void free_swap_index(int slot_index) { if (slot_index >= 0 && slot_index < SWAP_SIZE) thread_current()->swap_slots[slot_index] = false; } /* Flushes the chosen page to swap space */ void write_to_swap_space(struct spt_entry *target_entry) { target_entry->slot_index = allocate_swap_index(); int actual_sector_start_index = target_entry->slot_index * (PGSIZE/BLOCK_SECTOR_SIZE); if(target_entry->slot_index != -1) { const char *target_page = pagedir_get_page(thread_current()->pagedir, target_entry->vaddr); int current_sector_count = 0, end_count = PGSIZE/BLOCK_SECTOR_SIZE; while(current_sector_count < end_count) { // The start index for the slot should be adjusted by // PGSIZE / BLOCK_SECTOR_SIZE. block_write(block_get_role(BLOCK_SWAP), actual_sector_start_index + current_sector_count, target_page); ++current_sector_count; target_page += BLOCK_SECTOR_SIZE; } } } /* Reads a page from swap space */ void read_from_swap_space(void *kpage, int slot_index) { const char *target_page = kpage; int actual_sector_start_index = slot_index * (PGSIZE/BLOCK_SECTOR_SIZE); int current_sector_count = 0, end_count = PGSIZE/BLOCK_SECTOR_SIZE; while(current_sector_count < end_count) { // The start index for the slot should be adjusted by // PGSIZE / BLOCK_SECTOR_SIZE. block_read(block_get_role(BLOCK_SWAP), actual_sector_start_index + current_sector_count, target_page); ++current_sector_count; target_page += BLOCK_SECTOR_SIZE; } free_swap_index(slot_index); } - As a result, 8 block operations (
pick_victim_page()- This function implements the Clock Algorithm to select a page for eviction.
- It iterates through the current thread’s
supplemental_page_tablestarting fromcurrent_clock_index.- For each non-immortal, currently loaded page, it checks the page’s “accessed” bit.
- If the bit is set,
- it’s cleared, and the algorithm continues.
- If the bit is clear,
- that page is chosen as the victim.
- The
current_clock_indexis updated to continue the scan from the next page in the list.
- This ensures a fair and efficient selection process, favoring pages that haven’t been recently accessed.
Click to see the refined code
/* Selects a victim page to evict */ struct spt_entry* pick_victim_page() { struct thread *current_thread = thread_current(); struct spt_entry *target_spt_entry = NULL; bool is_full_cycle = false; struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table); struct list_elem *end_element = list_end(¤t_thread->supplemental_page_table); if (current_element == end_element) return NULL; // No pages to swap int current_index = 0; while (current_index < current_thread->current_clock_index && current_element != end_element) { current_element = list_next(current_element); ++current_index; } if (current_element == end_element) { current_thread->current_clock_index = 0; current_element = list_begin(¤t_thread->supplemental_page_table); } while (true) { if (current_element == end_element) { if (is_full_cycle) { // Completed a full cycle; force selection of first loaded page current_element = list_begin(¤t_thread->supplemental_page_table); current_index = 0; while (current_element != end_element) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if (target_spt_entry->is_immortal == false && pagedir_get_page(current_thread->pagedir, target_spt_entry->vaddr) != NULL) { current_thread->current_clock_index = current_index + 1; return target_spt_entry; } ++current_index; current_element = list_next(current_element); } return NULL; // No loaded pages found } current_thread->current_clock_index = 0; current_element = list_begin(¤t_thread->supplemental_page_table); is_full_cycle = true; continue; } // Process the page at current_clock_index target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if (target_spt_entry->is_immortal == false && pagedir_get_page(current_thread->pagedir, target_spt_entry->vaddr) != NULL) { if (pagedir_is_accessed(current_thread->pagedir, target_spt_entry->vaddr) == false) { ++current_thread->current_clock_index; return target_spt_entry; } pagedir_set_accessed(current_thread->pagedir, target_spt_entry->vaddr, false); } ++current_thread->current_clock_index; current_element = list_next(current_element); } }
evict_page()- This function orchestrates the eviction process.
- It first checks if the page’s data needs to be written back to disk.
- If the page is
SPT_ANON,- its contents are written to the swap space via
write_to_swap_space().
- its contents are written to the swap space via
- If it’s a file-backed page (
SPT_FILE) and has been modified (is dirty == true),- its contents are written back to the original file using
file_write_at().
- its contents are written back to the original file using
- If the page is
- The chosen physical page frame then is freed using
palloc_free_page(), and its mapping is cleared from the page directory.Click to see the refined code
/* Flushes the chosen page to swap space or the original physical address based on its type */ void evict_page(struct spt_entry* target_entry) { if(target_entry == NULL) return; struct thread *current_thread = thread_current(); // swap out DATA segment to SWAP SPACE as well if(target_entry->type == SPT_BIN) target_entry->type = SPT_ANON; if(target_entry->type == SPT_ANON) write_to_swap_space(target_entry); else { // this section is for mmap if(pagedir_is_dirty(current_thread->pagedir, target_entry->vaddr)) { file_write_at(target_entry->file, pagedir_get_page(current_thread->pagedir, target_entry->vaddr), PGSIZE, target_entry->offset); pagedir_set_dirty(current_thread->pagedir, target_entry->vaddr, false); } } palloc_free_page(pagedir_get_page(current_thread->pagedir, target_entry->vaddr)); pagedir_clear_page(current_thread->pagedir, target_entry->vaddr); }
handle_page_fault()- This function is now fully implemented to support page swapping.
- When
palloc_get_page()fails (indicating memory exhaustion), it callsevict_page()on three victim pages to free up memory before retrying the allocation. - If a physical page is successfully allocated (either initially or after eviction),
handle_page_fault()then determines where to load the page content from:- if
target_spt_entry->slot_indexindicates it’s in swap space,read_from_swap_space()is called.
- otherwise,
- the data is read from the original file via
file_read_at().
- the data is read from the original file via
Click to see the refined code
/* Handles the page fault */ bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); if (kpage == NULL) { // swap out 3 pages whenever memory becomes full for(int current_count = 0; current_count < 3; ++current_count) evict_page(pick_victim_page()); kpage = palloc_get_page (PAL_USER | PAL_ZERO); if(kpage == NULL) { // failed to evict if(is_lock_already_owned == false) lock_release(&filesys_lock); return false; } } // load the data from disk if(target_spt_entry->type == SPT_ANON) { // if the page is stored in swap space, read from there if(target_spt_entry->slot_index != -1) read_from_swap_space(kpage, target_spt_entry->slot_index); } else { // otherwise read from the disk if(file_read_at(target_spt_entry->file, kpage, target_spt_entry->read_bytes, target_spt_entry->offset) != target_spt_entry->read_bytes) { palloc_free_page (kpage); if(is_lock_already_owned == false) lock_release(&filesys_lock); return false; } } if(is_lock_already_owned == false) lock_release(&filesys_lock); // update page table if (!install_page (target_spt_entry->vaddr, kpage, target_spt_entry->writable)) { palloc_free_page (kpage); return false; } return true; } - if
- Functions for Swap Space
process.cload_segment()load_segment()now setsslot_indexto-1for newly created entries.- Moreover it marks certain crucial pages (code segment pages, and the first two data segment pages) as
is_immortal = trueto prevent their early eviction.Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { // other codes bool is_code_segment = current_thread->initial_code_segment == NULL; bool is_first_or_second_data_segment = true; bool temp_flag = true; while (read_bytes > 0 || zero_bytes > 0) { // other codes new_entry->vaddr = upage; if (current_thread->initial_code_segment == NULL) current_thread->initial_code_segment = upage; new_entry->zero_bytes = page_zero_bytes; new_entry->file = file; new_entry->read_bytes = page_read_bytes; new_entry->offset = ofs; new_entry->writable = writable; new_entry->slot_index = -1; if(is_code_segment || is_first_or_second_data_segment) { new_entry->is_immortal = true; if(temp_flag) temp_flag = false; else is_first_or_second_data_segment = false; } else new_entry->is_immortal = false; // other codse } return true; }
setup_stack()setup_stack()sets the initial stack page’sslot_indexto-1as well.- Furthermore, it initializes
is_immortaltotruesince it’s the first page of the stack.Click to see the refined code
static bool setup_stack (void **esp) { // other codes new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; new_entry->slot_index = -1; new_entry->is_immortal = true; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); return success; }
Conclusion
- With these enhancements, PintOS now provides robust support for demand paging and page swapping.
- The system can effectively handle page faults by loading pages on demand and can prevent memory exhaustion by evicting less-used pages to a dedicated swap space when physical memory becomes full.
- This significantly improves the system’s ability to run more processes concurrently and handle larger applications than available physical RAM.
- However, the current implementation still does not fully handle
mmap()and its associated memory mapping features, particularly in terms of dirty page management and direct file-backed page eviction logic, though preliminary provisions are included.- Further improvements are needed to fully support memory-mapped files and ensure seamless handling of all advanced memory operations, completing a comprehensive virtual memory subsystem.
Part 4: Memory Mapping Features
Objective
- The objective of the last part is to implement the
mmap()andmunmap()system calls in PintOS. - This functionality enables processes to directly map files into their virtual address space, allowing file contents to be accessed as if they were in memory, thereby enhancing I/O efficiency and facilitating inter-process communication.
Current Problem
- The previous PintOS didn’t support
mmap()andmunmap().
Solution
- Hence, I’ve implemented
mmap()andmunmap(), including new data structures and robust overlap checking:mmap_entryStructure:- A new data structure,
struct mmap_entry, has been created. - This structure acts as a container for all the necessary metadata related to a single memory-mapped file.
- It records a unique
map_idfor the mapping, the totalnumber_of_pagesspanned by the mapping, a pointer to themapped_fileobject, and a list (loaded_spt_entries) to manage all the individualspt_entryobjects that constitute this memory-mapped region.
- A new data structure,
- Thread-Specific
mmap_table:- Each thread’s
struct threadhas been extended to include anmmap_table, which is a list that stores all themmap_entryobjects currently active for that process. - This provides a clear, per-process record of all memory-mapped files.
- Each thread’s
- Overlap Detection:
- A critical function,
is_mmap_overlapped(), has been developed to prevent memory mapping conflicts. - This function ensures that new memory mapping requests do not overlap with existing memory mappings, the program’s code and data segments, or the stack region.
- To facilitate the data segment check, a new
final_data_segmentmember has been added tostruct thread.
- A critical function,
mmap()System Call Implementation:- The
mmap()system call now performs several crucial steps:- It validates the input arguments, including the file descriptor and the requested virtual address.
- It uses
file_reopen()to create a new, independent file object for the mapping.- This is vital to prevent interference with other file operations on the same underlying file.
- It calls
is_mmap_overlapped()to ensure the requested mapping region is free. - It allocates a new
mmap_entry, populates it with mapping details, and generates a uniquemap_id. - For each page within the mapped file, it creates a
SPT_FILEtypespt_entryand adds it to both themmap_entry’s internal list (loaded_spt_entries) and the thread’s overallsupplemental_page_table.- The
is_immortalflag for the first page of a mapping is set totrueto ensure its initial presence.
- The
- Finally, the
mmap_entryis added to the thread’smmap_table, and the uniquemap_idis returned to the user process.
- The
munmap()System Call Implementation:- The
munmap()system call handles the unmapping process:- It locates the
mmap_entrycorresponding to the providedmap_id. - It iterates through all
spt_entryobjects associated with thatmmap_entry.- For each page that is currently in physical memory and has been modified (dirty), its contents are written back to the original file.
- The physical page frames are then freed, and their mappings are cleared from the page directory.
- Finally, the
spt_entryobjects, themmap_entryitself, and the associated file object are properly closed and deallocated.
- It locates the
- The
- Integration with
process_exit()andpage_fault():process_exit()has been updated to automatically callmunmap()for any remainingmmap_entryobjects in a thread’smmap_tablewhen the process terminates.- This ensures proper cleanup and persistence of modified data.
page_fault()has been extended to also consult themmap_tablein addition to the regular supplemental page table.- If a page fault occurs for a virtual address within a memory-mapped region,
page_fault()now directshandle_page_fault()to load the appropriate file-backed page.
- If a page fault occurs for a virtual address within a memory-mapped region,
Implementation Details
- The following components have been modified or introduced:
page.hstruct mmap_entry- A new structure,
struct mmap_entry, has been defined to store memory mapping information. - This structure includes:
map_id: A unique identifier for the memory mapping.number_of_pages: The total number of memory pages involved in this mapping.mapped_file: A pointer to thefileobject being memory-mapped.loaded_spt_entries: A list ofspt_entryobjects that correspond to the pages loaded for this memory mapping.
Click to see the refined code
/* mmap_entry for mmap_table in each thread */ struct mmap_entry { int map_id; int number_of_pages; struct file *mapped_file; struct list loaded_spt_entries; // List for loaded spt_entry struct list_elem mmelem; // List element for mapping table };
- A new structure,
thread.hstruct thread- The
struct threadhas been enhanced by adding:mmap_table: A list designed to managemmap_entryobjects.current_available_map_id: An identifier that has been used for generating uniquemap_ids for new memory mappings.final_data_segment: A pointer that has marked the conclusion of the program’s data segment, which has been crucial for performing overlap checks during memory mapping operations.
Click to see the refined code
struct thread { // other codes bool *swap_slots; /* swap slot */ int current_clock_index; /* current index of page for clock algorithm*/ struct list mmap_table; /* memory mapping table for mmap() */ int current_available_map_id; /* id for mmap_entry */ void *final_data_segment; /* address of data segment */ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
- The
thread.cinit_thread()- Within
init_thread(), themmap_tableandcurrent_available_map_idhave been initialized for newly created threads.Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_clock_index = 0; list_init(&t->mmap_table); t->current_available_map_id = 0; old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
- Within
process.cload_segment()- This function has now set the
final_data_segmentfor the thread immediately after loading the executable’s data segment.Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { // other codes while (read_bytes > 0 || zero_bytes > 0) { // other codes ofs += PGSIZE; }/* Advance. */ if (is_code_segment == false) current_thread->final_data_segment = upage; return true; }
- This function has now set the
process_exit()- This function has been updated to call
munmap()on each remaining entry inmmap_table, thereby ensuring data persistence and proper resource deallocation when a process terminates.Click to see the refined code
void process_exit (void) { // other codes /* deallocate supplemental page table */ for(struct list_elem *current_element = list_begin(&cur->supplemental_page_table), *end_element = list_end(&cur->supplemental_page_table), *next_element; current_element != end_element;) { struct spt_entry *target_entry = list_entry(current_element, struct spt_entry, sptelem); next_element = list_next(current_element); list_remove(current_element); free(target_entry); current_element = next_element; } /* deallocate mmap table */ for(struct list_elem *current_element = list_begin(&cur->mmap_table), *end_element = list_end(&cur->mmap_table), *next_element; current_element != end_element;) { struct mmap_entry *target_mmap = list_entry(current_element, struct mmap_entry, mmelem); current_element = list_next(current_element); munmap(target_mmap->map_id); } // other codes }
- This function has been updated to call
syscall.cmmap()- This new function calls
file_reopen()to ensure thefileobject frommmap()is independent of any existing one. - It also utilizes
is_mmap_overlapped()to check for address space conflicts. - For the first page, it has set
is_immortaltotrue.Click to see the refined code
int mmap(int fd, void *addr) { struct thread *current_thread = thread_current(); lock_acquire(&filesys_lock); if(current_thread->fd_table[fd] == NULL || addr == NULL || is_user_vaddr(addr) == false || (uintptr_t)addr % PGSIZE != 0) { lock_release(&filesys_lock); return -1; } lock_release(&filesys_lock); struct mmap_entry *new_mmap_entry = malloc(sizeof(struct mmap_entry)); if(new_mmap_entry == NULL) exit(-1); list_init(&new_mmap_entry->loaded_spt_entries); new_mmap_entry->map_id = current_thread->current_available_map_id; ++current_thread->current_available_map_id; lock_acquire(&filesys_lock); // file_reopen() is needed to create a separate file object new_mmap_entry->mapped_file = file_reopen(current_thread->fd_table[fd]); int read_bytes = file_length(new_mmap_entry->mapped_file); new_mmap_entry->number_of_pages = (read_bytes + PGSIZE - 1) / PGSIZE; if(is_mmap_overlapped(addr, new_mmap_entry->number_of_pages) == true) { file_close(new_mmap_entry->mapped_file); --current_thread->current_available_map_id; free(new_mmap_entry); lock_release(&filesys_lock); return -1; } lock_release(&filesys_lock); int offset = 0; bool is_first_page = true; while (read_bytes > 0) { size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; struct spt_entry *new_spt_entry = malloc(sizeof(struct spt_entry)); if(new_spt_entry == NULL) return false; new_spt_entry->type = SPT_FILE; new_spt_entry->is_stack = false; new_spt_entry->vaddr = addr; new_spt_entry->zero_bytes = page_zero_bytes; new_spt_entry->file = new_mmap_entry->mapped_file; new_spt_entry->read_bytes = page_read_bytes; new_spt_entry->offset = offset; new_spt_entry->writable = true; new_spt_entry->slot_index = -1; if(is_first_page) { new_spt_entry->is_immortal = true; is_first_page = false; } else new_spt_entry->is_immortal = false; list_push_back(&new_mmap_entry->loaded_spt_entries, &new_spt_entry->sptelem); // Advance. read_bytes -= page_read_bytes; addr += PGSIZE; offset += PGSIZE; } list_push_back(¤t_thread->mmap_table, &new_mmap_entry->mmelem); return new_mmap_entry->map_id; }
- This new function calls
is_mmap_overlapped()- This new function checks all
mmap_entryobjects for overlaps. - Moreover, it verifies that the given memory range does not conflict with the area before the end of the data segment or after the top of the stack segment.
Click to see the refined code
bool is_mmap_overlapped(void *vaddr_start, int number_of_pages) { struct thread *current_thread = thread_current(); void *vaddr_end = vaddr_start + number_of_pages * PGSIZE; void *mmap_start = NULL, *mmap_end = NULL; for(struct list_elem *current_element_mmap = list_begin(¤t_thread->mmap_table), *end_element_mmap = list_end(¤t_thread->mmap_table); current_element_mmap != end_element_mmap; current_element_mmap = list_next(current_element_mmap)) { struct mmap_entry *current_mmap_entry = list_entry(current_element_mmap, struct mmap_entry, mmelem); for(struct list_elem *current_element_spt = list_begin(¤t_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(¤t_mmap_entry->loaded_spt_entries); current_element_spt != end_element_spt; current_element_spt = list_next(current_element_spt)) { struct spt_entry *current_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); mmap_start = current_spt_entry->vaddr; mmap_end = mmap_start + PGSIZE; if (!(vaddr_end <= mmap_start || vaddr_start >= mmap_end)) return true; } } // check data segment if (vaddr_start < current_thread->final_data_segment) return true; // check stack if (vaddr_end > thread_current()->current_stack_top) return true; return false; }
- This new function checks all
munmap()- This new function removes the target
mmap_entryfrom the current thread’smmap_table. - It then closes the corresponding
fileobject, and frees all pages along with their associatedspt_entryobjects related to the targetmmap_entry.Click to see the refined code
void munmap(int map_id) { struct thread *current_thread = thread_current(); struct mmap_entry *target_mmap_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->mmap_table), *end_element = list_end(¤t_thread->mmap_table); current_element != end_element; current_element = list_next(current_element)) { target_mmap_entry = list_entry(current_element, struct mmap_entry, mmelem); if(target_mmap_entry->map_id == map_id) { list_remove(current_element); break; } } if(target_mmap_entry == NULL) exit(-1); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); for(struct list_elem *current_element_spt = list_begin(&target_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(&target_mmap_entry->loaded_spt_entries), *next_element_spt; current_element_spt != end_element_spt;) { struct spt_entry *current_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); next_element_spt = list_next(current_element_spt); list_remove(current_element_spt); if(pagedir_is_dirty(current_thread->pagedir, current_spt_entry->vaddr)) { file_write_at(current_spt_entry->file, pagedir_get_page(current_thread->pagedir, current_spt_entry->vaddr), current_spt_entry->read_bytes, current_spt_entry->offset); pagedir_set_dirty(current_thread->pagedir, current_spt_entry->vaddr, false); } palloc_free_page(pagedir_get_page(current_thread->pagedir, current_spt_entry->vaddr)); pagedir_clear_page(current_thread->pagedir, current_spt_entry->vaddr); free(current_spt_entry); current_element_spt = next_element_spt; } file_close(target_mmap_entry->mapped_file); if(is_lock_already_owned == false) lock_release(&filesys_lock); free(target_mmap_entry); }
- This new function removes the target
syscall_handler()- It has been modified to appropriately dispatch calls to the new
mmap()andmunmap()functions.Click to see the refined code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { // other codes case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; } }
- It has been modified to appropriately dispatch calls to the new
exception.cpage_fault()- The page fault handler has been fully revised.
- Therefore, it now checks
mmap_tableentries when resolving page faults, allowing it to correctly load file-backed pages on demand.
Click to see the refined code
static void page_fault (struct intr_frame *f) { // other codes // handle page demanding struct spt_entry *target_spt_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table), *end_element = list_end(¤t_thread->supplemental_page_table); current_element != end_element; current_element = list_next(current_element)) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } // handle memory-mapped file for(struct list_elem *current_element_mmap = list_begin(¤t_thread->mmap_table), *end_element_mmap = list_end(¤t_thread->mmap_table); current_element_mmap != end_element_mmap; current_element_mmap = list_next(current_element_mmap)) { struct mmap_entry *current_mmap_entry = list_entry(current_element_mmap, struct mmap_entry, mmelem); for(struct list_elem *current_element_spt = list_begin(¤t_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(¤t_mmap_entry->loaded_spt_entries); current_element_spt != end_element_spt; current_element_spt = list_next(current_element_spt)) { target_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } } // other codes } - Therefore, it now checks
- The page fault handler has been fully revised.
Conclusion
- PintOS now has full features for memory management, including paging, page swapping, and memory mapping.
- The system handles file-backed pages, stack growth, and ensures proper management of both anonymous and memory-mapped pages.
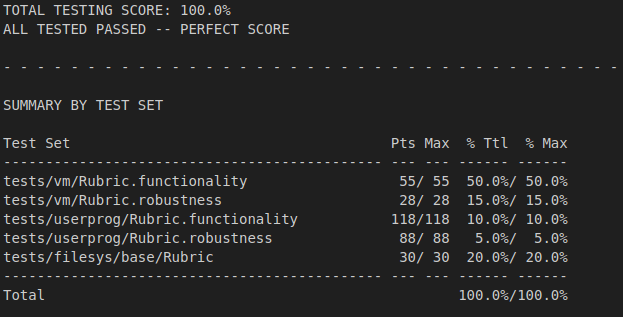
Improved Grade
Final Thoughts
- PintOS’s memory management has significantly advanced with integrated demand paging, robust page swapping, and full memory mapping support.
- This optimizes memory utilization by allocating pages on demand, manages pressure via intelligent eviction, and ensures data persistence, resulting in a more resilient and performant OS for complex applications.
Leave a comment