Project 4: File Systems
File Systems
- The fourth project fills the last part to complete the ultimate PintOS.
- This final stage involves:
- Implementing a buffer cache.
- Making files extensible.
- Introducing subdirectories.
-
Below, I outlined the objectives, challenges, solutions, and implementations for each component.
Part 1: Buffer Cache
Objective
- The primary objective is to implement a buffer cache to optimize disk I/O operations.
- This involved routing disk reads and writes through a buffer cache in memory, thereby significantly enhancing overall system performance by reducing direct access to the slower disk.
Current Problem
- The current PintOS lacks a buffer cache.
- Consequently, the original
block_read()andblock_write()functions directly access the disk every time they are invoked, leading to inefficient I/O operations.
Click to see the original code
void block_read (struct block *block, block_sector_t sector, void *buffer) { check_sector (block, sector); block->ops->read (block->aux, sector, buffer); block->read_cnt++; } void block_write (struct block *block, block_sector_t sector, const void *buffer) { check_sector (block, sector); ASSERT (block->type != BLOCK_FOREIGN); block->ops->write (block->aux, sector, buffer); block->write_cnt++; } - Consequently, the original
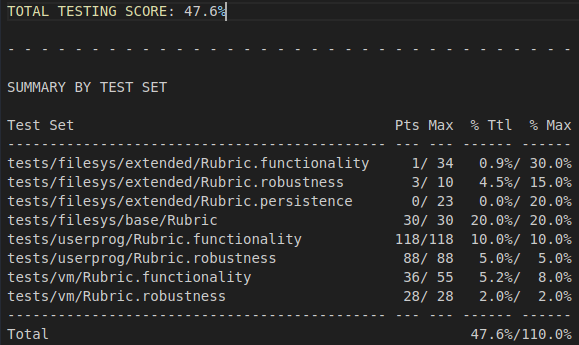
Original Grade
Solution
- To implement a concept of the buffer cache, I introduced:
block_read_buffer_cache()andblock_write_buffer_cache()- These are the new primary functions responsible for handling all disk read and write requests from higher levels of the file system.
- They serve as the interface to the buffer cache.
- When
block_read_buffer_cache()is invoked,- it first checks if the requested block is present in the cache.
- If so (cache hit), it directly provides the data from memory.
- If the block is not in the cache (cache miss), it loads the block from the physical disk into a cache entry before returning the data.
- it first checks if the requested block is present in the cache.
- When
block_write_buffer_cache()is invoked,- it writes the data to the corresponding block in the buffer cache.
- If the block is not already cached (cache miss), it first loads the block from the disk into the cache, then performs the write.
- The cache entry is then marked as “dirty” to indicate that its content differs from the disk.
- it writes the data to the corresponding block in the buffer cache.
- I made the file system flush the buffer cache in these cases:
- Eviction-based Flush
- If the buffer cache becomes full and a new block needs to be loaded, the
evict_buffer_cache_entry()function is called. - This function employs the clock algorithm to select a victim block.
- If the chosen victim block is dirty, its contents are flushed (written back) to the disk before the cache entry is repurposed for the new block.
- If the buffer cache becomes full and a new block needs to be loaded, the
- Periodic Flush
- A dedicated kernel thread, launched during
filesys_init(), runs in the background.- It periodically wakes up (every 5 seconds) and scans the entire
cached_mapping_tablefor any dirty blocks.
- It periodically wakes up (every 5 seconds) and scans the entire
- Any dirty blocks found are asynchronously written back to the disk, proactively saving changes and reducing the amount of data that needs to be written during eviction or shutdown.
- A dedicated kernel thread, launched during
- System Shutdown Flush
- Upon system termination (
filesys_done()), all remaining dirty blocks in the buffer cache are explicitly flushed to disk, guaranteeing that all persistent data is written before the system powers off.
- Upon system termination (
- Eviction-based Flush
- To achieve this solution:
- I defined
struct buffer_entryto represent each individual cache block.- It holds its device, sector, memory address, and crucial
is_dirtyandis_accessedflags.
- It holds its device, sector, memory address, and crucial
- A global array,
cached_mapping_table, serves as the main buffer cache, storing thesebuffer_entrystructures.- A global
buffer_cache_lockensures mutual exclusion and thread safety when accessing or modifying thecached_mapping_table. - Synchronization is further extended to the
struct inodeitself with aninode_lockto protect inode data during concurrent access.
- A global
- Crucially, the existing
inode_read_at()andinode_write_at()functions are re-implemented to utilize the newblock_read_buffer_cache()andblock_write_buffer_cache()functions, effectively rerouting all file I/O through the buffer cache. - Thread management is subtly adapted by adding
parent_thread_pointertostruct thread, which aids in syscall validation (is_valid_address()) by allowing access to parent page directories. - Finally, the
handle_page_fault()function is carefully modified to temporarily release thebuffer_cache_lockif held during a page fault, preventing potential deadlocks when the fault handler itself might need to perform I/O.
- I defined
Implementation Details
- The following components have been modified or introduced:
block.hstruct buffer_entry- This new structure serves as an entry for each cached block within the buffer cache.
Click to see the refined code
/* Entry for each block in a buffer cache */ struct buffer_entry { struct block *target_block_device; /* target block device */ block_sector_t sector_index; /* physical address of this block in the disk */ void *cached_block; /* pointer to the actual address in memory for the cached block */ bool is_dirty; /* flag to check whether this block is modified or not */ bool is_accessed; /* flag for choosing a victim for the eviction */ };
- This new structure serves as an entry for each cached block within the buffer cache.
cached_mapping_table- This is a global array of
buffer_entrystructures, representing the entire buffer cache. - It is initialized during
filesys_init()and its entries are flushed to disk when necessary,- such as upon system shutdown (
filesys_done()) or eviction of a certain block in the buffer cache.
Click to see the refined code
/* Buffer Cache */ #define BUFFER_CACHE_MAX_COUNT 64 struct buffer_entry cached_mapping_table[BUFFER_CACHE_MAX_COUNT]; - such as upon system shutdown (
- This is a global array of
buffer_cache_lock- A global lock mechanism protects the
cached_mapping_tableto ensure thread-safe access to the buffer cache. - This lock is also initialized within
filesys_init().Click to see the refined code
/* Buffer Cache */ struct lock buffer_cache_lock;
- A global lock mechanism protects the
New Function Declarations- Declares
block_read_buffer_cache()andblock_write_buffer_cache().- These functions are the new interfaces for reading from and writing to the disk through the buffer cache.
Click to see the refined code
void block_read_buffer_cache(struct block *block, block_sector_t sector, void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset); void block_write_buffer_cache(struct block *block, block_sector_t sector, const void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset);
- Declares
New Header Files- Three header files (
synch.h,vaddr.h,palloc.h) are included to support the buffer cache’s functionality.Click to see the refined code
#include "threads/synch.h" #include "threads/vaddr.h" #include "threads/palloc.h"
- Three header files (
filesys.hNew Header Files- Includes
block.hfor the modified code infilesys.c.Click to see the refined code
#include "devices/block.h"
- Includes
filesys.cflush_buffer_cache()- This function is executed by a separate thread, launched during
filesys_init(). - Its purpose is to periodically iterate through the buffer cache, identify any modified (
is_dirty) blocks, and write them back to the disk.- This asynchronous flushing helps maintain data consistency without blocking regular I/O operations.
- The
timer.hheader is included to facilitate the periodic flushing mechanism.Click to see the refined code
#include "devices/timer.h" // other codes /* Periodically checks whether there's a dirty block. If there is, flush it */ void * flush_buffer_cache(void *arg) { while (is_terminated == false) { timer_sleep(TIMER_FREQ * 5); // waiting for 5 seconds lock_acquire(&buffer_cache_lock); for (int current_block_index = 0; current_block_index < BUFFER_CACHE_MAX_COUNT; ++current_block_index) { if (cached_mapping_table[current_block_index].target_block_device != NULL && cached_mapping_table[current_block_index].is_dirty) { // Flush! block_write(cached_mapping_table[current_block_index].target_block_device, cached_mapping_table[current_block_index].sector_index, cached_mapping_table[current_block_index].cached_block); cached_mapping_table[current_block_index].is_dirty = false; } } lock_release(&buffer_cache_lock); } return NULL; }
- This function is executed by a separate thread, launched during
filesys_init()- This function now includes logic to initialize the buffer cache.
- It sets up the
buffer_cache_lockand allocates memory pages for the cache entries. - Importantly, it also creates and launches the dedicated thread that calls
flush_buffer_cache()periodically.
Click to see the refined code
void filesys_init (bool format) { // Initialize buffer cache lock_init(&buffer_cache_lock); char *buffer_cache_page = palloc_get_page(PAL_USER | PAL_ZERO); for( int current_entry_index = 0, end_page_count = PGSIZE/BLOCK_SECTOR_SIZE, current_page_count = 0 ; current_entry_index < BUFFER_CACHE_MAX_COUNT ; ++current_entry_index, ++current_page_count) { if(current_page_count == end_page_count) { current_page_count = 0; buffer_cache_page = palloc_get_page(PAL_USER | PAL_ZERO); } cached_mapping_table[current_entry_index].target_block_device = NULL; cached_mapping_table[current_entry_index].cached_block = buffer_cache_page; buffer_cache_page += BLOCK_SECTOR_SIZE; } fs_device = block_get_role (BLOCK_FILESYS); // other codes dir_add (root_dir, ".", ROOT_DIR_SECTOR); // Execute dedicated thread for flushing the buffer cache periodically thread_create("bc_flusher", PRI_DEFAULT, flush_buffer_cache, NULL); } - It sets up the
- This function now includes logic to initialize the buffer cache.
filesys_done()- When the file system is being shut down,
filesys_done()is extended to ensure all dirty blocks in the buffer cache are written back to the disk before resources are deallocated.
- This guarantees that no data is lost upon system termination.
Click to see the refined code
void filesys_done (void) { free_map_close (); /* buffer cache */ void *buffer_cache_page = cached_mapping_table[0].cached_block; for( int current_entry_index = 0, end_page_count = PGSIZE/BLOCK_SECTOR_SIZE, current_page_count = 0 ; current_entry_index < BUFFER_CACHE_MAX_COUNT ; ++current_entry_index, ++current_page_count) { if(current_page_count == end_page_count) { current_page_count = 0; palloc_free_page (buffer_cache_page); buffer_cache_page = cached_mapping_table[current_entry_index].cached_block; } // flush modified block if(cached_mapping_table[current_entry_index].is_dirty) block_write (cached_mapping_table[current_entry_index].target_block_device , cached_mapping_table[current_entry_index].sector_index , cached_mapping_table[current_entry_index].cached_block); } }
- When the file system is being shut down,
block.cblock_read_buffer_cache()- This new function manages read requests.
- It first checks if the requested block is already present in the
cached_mapping_table(cache hit).- If a cache miss occurs, it attempts to find an empty slot.
- If the cache is full, it invokes
evict_buffer_cache_entry()to make space.
- After determining the target cache entry,
- it reads the block from the disk into the cache if necessary, copies the data to the user’s buffer, and marks the entry as accessed.
- Synchronization is handled using
buffer_cache_lock.
- It first checks if the requested block is already present in the
- The function accommodates partial block reads using two offsets and chunk size parameters,
- which are crucial for handling bounce buffers.
Click to see the refined code
/* Reads from buffer cache */ void block_read_buffer_cache (struct block *block, block_sector_t sector, void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset) { lock_acquire(&buffer_cache_lock); int current_entry_index = 0, temp_available_index = -1; for(; current_entry_index < BUFFER_CACHE_MAX_COUNT; ++current_entry_index) { if(temp_available_index == -1 && cached_mapping_table[current_entry_index].target_block_device == NULL) temp_available_index = current_entry_index; if(cached_mapping_table[current_entry_index].target_block_device != NULL && cached_mapping_table[current_entry_index].sector_index == sector) { break; } } if(current_entry_index == BUFFER_CACHE_MAX_COUNT) { // cache miss! // find free block if(temp_available_index == -1) { // if buffer cache is full, evict just like paging current_entry_index = evict_buffer_cache_entry(); } else current_entry_index = temp_available_index; // read block from disk block_read(block, sector, cached_mapping_table[current_entry_index].cached_block); // update entry cached_mapping_table[current_entry_index].target_block_device = block; cached_mapping_table[current_entry_index].sector_index = sector; cached_mapping_table[current_entry_index].is_dirty = false; } // cache hit! memcpy(buffer + buffer_offset, cached_mapping_table[current_entry_index].cached_block + cache_offset, chunk_size); cached_mapping_table[current_entry_index].is_accessed = true; lock_release(&buffer_cache_lock); }
- This new function manages read requests.
evict_buffer_cache_entry()- This function implements the clock algorithm to select a victim entry for eviction when the buffer cache is full.
- It iterates through the cache entries, looking for blocks that have not been recently accessed (
is_accessed == false). - If a dirty block is selected for eviction, its content is flushed to disk before the entry is reused.
Click to see the refined code
/* Evicts the least recently used block in buffer cache by using the clock algorithm Returns the index of it. */ int evict_buffer_cache_entry() { static int current_clock_index = 0; bool is_full_cycle = false; int target_entry_index = current_clock_index; while(true) { if(current_clock_index == BUFFER_CACHE_MAX_COUNT) { current_clock_index = 0; if(is_full_cycle) { // Completed a full cycle; force selection of first loaded block // flush it if it's modified if(cached_mapping_table[current_clock_index].is_dirty) { block_write(cached_mapping_table[current_clock_index].target_block_device, cached_mapping_table[current_clock_index].sector_index, cached_mapping_table[current_clock_index].cached_block); } target_entry_index = current_clock_index; break; } else is_full_cycle = true; } if(cached_mapping_table[current_clock_index].is_accessed == false) { // flush it if it's modified if(cached_mapping_table[current_clock_index].is_dirty) { block_write(cached_mapping_table[current_clock_index].target_block_device, cached_mapping_table[current_clock_index].sector_index, cached_mapping_table[current_clock_index].cached_block); } target_entry_index = current_clock_index; break; } else cached_mapping_table[current_clock_index].is_accessed = false; ++current_clock_index; } ++current_clock_index; if(current_clock_index == BUFFER_CACHE_MAX_COUNT) current_clock_index = 0; return target_entry_index; } - It iterates through the cache entries, looking for blocks that have not been recently accessed (
- This function implements the clock algorithm to select a victim entry for eviction when the buffer cache is full.
block_write_buffer_cache()- This new function handles write requests.
- Similar to
block_read_buffer_cache(), it first checks for a cache hit.- If a miss occurs and no free slot is available, it calls
evict_buffer_cache_entry()to create space. - The function then writes the provided data into the cached block, marks the entry as dirty (indicating it has been modified), and sets its accessed flag.
- If a miss occurs and no free slot is available, it calls
- Synchronization is maintained with
buffer_cache_lock.
- Similar to
- This function also supports partial block writes by using two offsets and chunk size parameters.
Click to see the refined code
/* Writes sector to buffer cache */ void block_write_buffer_cache(struct block *block, block_sector_t sector, const void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset) { lock_acquire(&buffer_cache_lock); int current_entry_index = 0, temp_available_index = -1; for(; current_entry_index < BUFFER_CACHE_MAX_COUNT; ++current_entry_index) { if(temp_available_index == -1 && cached_mapping_table[current_entry_index].target_block_device == NULL) temp_available_index = current_entry_index; if(cached_mapping_table[current_entry_index].target_block_device != NULL && cached_mapping_table[current_entry_index].sector_index == sector) { break; } } if(current_entry_index == BUFFER_CACHE_MAX_COUNT) { // cache miss! // find free block if(temp_available_index == -1) { // if buffer cache is full, evict just like paging current_entry_index = evict_buffer_cache_entry(); } else current_entry_index = temp_available_index; // read from the disk block_read(block, sector, cached_mapping_table[current_entry_index].cached_block); // update entry cached_mapping_table[current_entry_index].target_block_device = block; cached_mapping_table[current_entry_index].sector_index = sector; } // update entry memcpy(cached_mapping_table[current_entry_index].cached_block + cache_offset, buffer + buffer_offset, chunk_size); cached_mapping_table[current_entry_index].is_dirty = true; cached_mapping_table[current_entry_index].is_accessed = true; lock_release(&buffer_cache_lock); }
- This new function handles write requests.
inode.cstruct inode- A new
inode_lockis added to thestruct inodeto ensure thread-safe access to individual inode data.- This lock is initialized when an inode is opened via
inode_open().
Click to see the refined code
/* In-memory inode. */ struct inode { struct list_elem elem; /* Element in inode list. */ block_sector_t sector; /* Sector number of disk location. */ int open_cnt; /* Number of openers. */ bool removed; /* True if deleted, false otherwise. */ int deny_write_cnt; /* 0: writes ok, >0: deny writes. */ struct inode_disk data; /* Inode content. */ struct lock inode_lock; /* Lock for synchronization */ }; - This lock is initialized when an inode is opened via
- A new
inode_open()- This function now initializes the
inode_lockwithin the opened inode structure. - It also uses
block_read_buffer_cache()to load the inode’s disk data into memory when it is opened.Click to see the refined code
struct inode * inode_open (block_sector_t sector) { // other codes inode->removed = false; lock_init(&inode->inode_lock); block_read_buffer_cache (fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); return inode; }
- This function now initializes the
inode_read_at()- This function is modified to use
block_read_buffer_cache()instead ofblock_read()for all disk reads.- It acquires and releases the
inode_lockto protect the inode’s internal data during read operations, ensuring data consistency across concurrent accesses.
Click to see the refined code
off_t inode_read_at (struct inode *inode, void *buffer_, off_t size, off_t offset) { uint8_t *buffer = buffer_; off_t bytes_read = 0; lock_acquire(&inode->inode_lock); while (size > 0) { /* Disk sector to read, starting byte offset within sector. */ block_sector_t sector_idx = byte_to_sector (inode, offset); lock_release(&inode->inode_lock); int sector_ofs = offset % BLOCK_SECTOR_SIZE; /* Bytes left in inode, bytes left in sector, lesser of the two. */ off_t inode_left = inode_length (inode) - offset; int sector_left = BLOCK_SECTOR_SIZE - sector_ofs; int min_left = inode_left < sector_left ? inode_left : sector_left; /* Number of bytes to actually copy out of this sector. */ int chunk_size = size < min_left ? size : min_left; if (chunk_size <= 0) { lock_acquire(&inode->inode_lock); break; } // read from buffer cache block_read_buffer_cache (fs_device, sector_idx, buffer, bytes_read, chunk_size, sector_ofs); /* Advance. */ size -= chunk_size; offset += chunk_size; bytes_read += chunk_size; lock_acquire(&inode->inode_lock); } lock_release(&inode->inode_lock); return bytes_read; } - It acquires and releases the
- This function is modified to use
inode_write_at()- Similarly,
inode_write_at()is updated to useblock_write_buffer_cache()for all disk writes.- It also incorporates
inode_lockfor synchronization, protecting the inode’s data during write operations, including when the file length needs to grow.
Click to see the refined code
off_t inode_write_at (struct inode *inode, const void *buffer_, off_t size, off_t offset) { const uint8_t *buffer = buffer_; off_t bytes_written = 0; if (inode->deny_write_cnt) return 0; lock_acquire(&inode->inode_lock); if(inode->data.length < offset + size) { if(!grow_file_length (&inode->data, inode->data.length, offset + size)) exit(-1); block_write_buffer_cache(fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); } while (size > 0) { /* Sector to write, starting byte offset within sector. */ block_sector_t sector_idx = byte_to_sector (inode, offset); lock_release(&inode->inode_lock); int sector_ofs = offset % BLOCK_SECTOR_SIZE; /* Bytes left in inode, bytes left in sector, lesser of the two. */ off_t inode_left = inode_length (inode) - offset; int sector_left = BLOCK_SECTOR_SIZE - sector_ofs; int min_left = inode_left < sector_left ? inode_left : sector_left; /* Number of bytes to actually write into this sector. */ int chunk_size = size < min_left ? size : min_left; if (chunk_size <= 0) { lock_acquire(&inode->inode_lock); break; } // write to buffer cache block_write_buffer_cache(fs_device, sector_idx, buffer, bytes_written, chunk_size, sector_ofs); /* Advance. */ size -= chunk_size; offset += chunk_size; bytes_written += chunk_size; lock_acquire(&inode->inode_lock); } lock_release(&inode->inode_lock); return bytes_written; } - It also incorporates
- Similarly,
thread.hstruct thread- A new member,
parent_thread_pointer, is added to thestruct thread.- This pointer allows child threads to access information related to their parent, which is particularly useful for shared resources and inheritance, such as directory information or page directories in certain scenarios.
Click to see the refined code
// other codes struct thread *parent_thread_pointer; /* pointer to its parent thread */ // other codes
- A new member,
thread.cinit_thread()- Initializes
parent_thread_pointerasNULLby default.Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_clock_index = 0; list_init(&t->mmap_table); t->current_available_map_id = 0; t->parent_thread_pointer = NULL; // initializes as NULL old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
- Initializes
thread_create()- When a new child thread is created,
thread_create()explicitly sets the new thread’sparent_thread_pointerto the currently executing thread, establishing the parent-child relationship.Click to see the refined code
tid_t thread_create (const char *name, int priority, thread_func *function, void *aux) { // other codes #ifdef USERPROG /* push child process to parent */ list_push_back(&thread_current()->children, &t->childelem); #endif /* Update pointer to its parent thread */ t->parent_thread_pointer = thread_current(); /* Add to run queue. */ thread_unblock(t); if(t->priority > thread_current()->priority) thread_yield(); return tid; }
- When a new child thread is created,
syscall.cis_valid_address()- This function, responsible for validating user-provided memory addresses, is enhanced.
- It now checks the current thread’s page directory, and if the address is not found there, it attempts to look up the address in the parent thread’s page directory.
- This revision handles scenarios where shared memory regions or inherited resources might reside in the parent’s address space.
Click to see the refined code
bool is_valid_address(void *ptr) { if(ptr != NULL && is_user_vaddr(ptr) == true) { if(pagedir_get_page(thread_current()->pagedir, ptr) != NULL) return true; else { if(thread_current()->parent_thread_pointer != NULL && thread_current()->parent_thread_pointer->pagedir != NULL && pagedir_get_page(thread_current()->parent_thread_pointer->pagedir, ptr) != NULL) { return true; } } } return false; }
- This function, responsible for validating user-provided memory addresses, is enhanced.
page.chandle_page_fault()- This function, which handles page fault exceptions, is modified to correctly manage locks when a page fault occurs.
- Specifically, if
buffer_cache_lockis held by the current thread when a page fault occurs,- the lock is temporarily released before handling the fault and reacquired afterward.
- This prevents potential deadlocks or re-entrancy issues where the page fault handler itself might need to access the disk, which could otherwise lead to recursive lock attempts.
Click to see the refined code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); // now it handles buffer_cache_lock bool is_buffer_lock_already_owned = lock_held_by_current_thread(&buffer_cache_lock); if(is_buffer_lock_already_owned == true) lock_release(&buffer_cache_lock); // other codes // now it handles buffer_cache_lock if(is_buffer_lock_already_owned == true) lock_acquire(&buffer_cache_lock); if(is_lock_already_owned == false) lock_release(&filesys_lock); // other codes } - Specifically, if
- This function, which handles page fault exceptions, is modified to correctly manage locks when a page fault occurs.
Conclusion
- With the successful implementation of the buffer cache, PintOS now significantly enhances its file I/O performance by minimizing direct disk access.
- This crucial component optimizes data transfer and reduces latency for file system operations.
- However, two additional objectives remain to fully complete the final project, which are addressed in the subsequent sections.
Part 2: Extensible Files
Objective
- The primary objective of this section is to modify the file system to enable dynamic file size changes, allowing files to grow as needed.
Current Problem
- The current PintOS limits file extensibility.
- The original
struct inode_diskincludes only astartsector, pointing to what is essentially a single, contiguous data block. - While the length field indicates the file’s size, this design inherently prevents files from spanning non-contiguous disk blocks.
- Consequently, if a file needs to expand beyond its initially allocated contiguous space, it cannot do so easily due to the absence of a mechanism within the inode to reference additional, disparate data blocks.
- The original
-
This significantly restricts file growth and overall file system flexibility.
Click to see the original code
struct inode_disk { block_sector_t start; /* First data sector. */ off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ uint32_t unused[125]; /* Not used. */ };
Solution
- The core solution involves a fundamental redesign of
struct inode_diskto support a hierarchical block addressing scheme, replacing the singlestartpointer with a combination of direct and indirect pointers.- This revised structure allows files to dynamically expand by referencing multiple, potentially non-contiguous, data blocks across the disk.
- This change significantly increases the maximum supported file size to approximately
8 MB.
- To integrate this new extensible file mechanism into the file system, several key functions are re-implemented or introduced:
byte_to_sector()- This function is modified to correctly translate a given file offset into its corresponding physical disk sector, navigating through the new direct, single-indirect, and double-indirect block pointers.
inode_create()- This function is re-implemented to utilize the new block allocation strategy when initially creating a file, ensuring that the necessary data blocks are reserved for its initial size.
inode_close()- This function is updated to properly deallocate all data blocks associated with an inode when the file is removed.
grow_file_length()- A new utility function is introduced specifically to manage the dynamic allocation of new disk blocks when a file needs to extend its size.
- This function is utilized by
inode_create()for initial allocation and byinode_write_at()during writes that extend the file.
free_data_blocks()- A new function is created to recursively traverse and release all disk sectors (direct, single-indirect, and double-indirect) associated with an
inode_diskstructure back to the free map.
- A new function is created to recursively traverse and release all disk sectors (direct, single-indirect, and double-indirect) associated with an
Implementation Details
- The following components have been modified or introduced:
inode.cstruct inode_disk- This structure is fundamentally revised to incorporate a new block mapping scheme.
- It now includes 124
direct_data_block_tableentries, which are sector indices pointing directly to data blocks. - Additionally, it introduces
single_indirect_data_block_sector_indexanddouble_indirect_data_block_sector_index.- These indirect pointers point to other blocks that, in turn, contain lists of further data block sector indices.
- The number
124for direct entries is strategically chosen to fully utilize the remaining space within a single disk sector dedicated to theinode_diskstructure, maximizing efficiency.
- It now includes 124
- The introduction of indirect blocks dramatically extends the file system’s ability to address a much larger number of data blocks.
Click to see the refined code
#define DIRECT_BLOCK_ENTRIES 124 #define INDIRECT_BLOCK_ENTRIES (BLOCK_SECTOR_SIZE / sizeof (block_sector_t)) struct inode_disk { off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ block_sector_t direct_data_block_table [DIRECT_BLOCK_ENTRIES]; block_sector_t single_indirect_data_block_sector_index; block_sector_t double_indirect_data_block_sector_index; };
- This structure is fundamentally revised to incorporate a new block mapping scheme.
byte_to_sector()- This function’s logic is entirely revised to support the new
inode_diskstructure.- Given a file offset, it now intelligently determines whether the corresponding data block is referenced via a direct pointer, a single-indirect pointer, or a double-indirect pointer.
- It reads the necessary intermediate index blocks from the buffer cache to locate the final data sector.
Click to see the refined code
static block_sector_t byte_to_sector (const struct inode *inode, off_t target_position) { ASSERT (inode != NULL); if (target_position >= inode->data.length) return -1; off_t block_index = target_position / BLOCK_SECTOR_SIZE; if(block_index < DIRECT_BLOCK_ENTRIES) return inode->data.direct_data_block_table[block_index]; block_index -= DIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES) { block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode->data.single_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); return indirect_table[block_index]; } block_index -= INDIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES * INDIRECT_BLOCK_ENTRIES) { block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode->data.double_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); int double_block_index = block_index/INDIRECT_BLOCK_ENTRIES; block_read_buffer_cache(fs_device, indirect_table[double_block_index], indirect_table, 0, BLOCK_SECTOR_SIZE, 0); return indirect_table[block_index - double_block_index * INDIRECT_BLOCK_ENTRIES]; } return exit(-1); }
- This function’s logic is entirely revised to support the new
grow_file_length()- This crucial new function manages the dynamic allocation of data blocks when a file’s length increases.
- It takes the current and target new length as arguments.
- It iteratively allocates new sectors from the free map as needed to accommodate the growth.
- The function meticulously handles the allocation of direct blocks, single-indirect blocks (including the indirect table itself), and double-indirect blocks (including both levels of indirect tables), ensuring that all newly allocated blocks are initialized with zeros for data integrity.
- The newly created tables are initialized as -1.
- This function is called by
inode_create()for initial allocation and byinode_write_at()when a write operation extends the file.Click to see the refined code
/* Handles the extension of the file The caller of this function should write modifiied inode_disk to disk */ static bool grow_file_length (struct inode_disk *inode_disk, off_t length, off_t new_length) { static char zeros[BLOCK_SECTOR_SIZE]; if (length == new_length) return true; // if the request is to decrease the size, then block it if (length > new_length) return false; inode_disk->length = new_length; off_t number_of_blocks_allocated = 0; // align the length as BLOCK_SECTOR_SIZE // adjustment is needed to calculate the block index properly when length is 512, 1024, ... if (length > 0) number_of_blocks_allocated = (length - 1) / BLOCK_SECTOR_SIZE + 1; off_t number_of_blocks_to_allocate = (new_length - 1) / BLOCK_SECTOR_SIZE + 1; block_sector_t double_indirect_table[INDIRECT_BLOCK_ENTRIES], single_indirect_table[INDIRECT_BLOCK_ENTRIES]; block_sector_t sector; off_t block_index; for (off_t cur_allocated_blocks = number_of_blocks_allocated; cur_allocated_blocks < number_of_blocks_to_allocate; ++cur_allocated_blocks) { sector = 0; block_index = cur_allocated_blocks; if(block_index < DIRECT_BLOCK_ENTRIES) { // case for direct if(inode_disk->direct_data_block_table[block_index] == (block_sector_t) -1) { // if current block index is not allocated, allocate new sector if (!free_map_allocate (1, §or)) return false; inode_disk->direct_data_block_table[block_index] = sector; } // if the sector has been already allocated, then it's good to go } else { // case for indirect block_index -= DIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES) { // case for single-indirect if (inode_disk->single_indirect_data_block_sector_index == (block_sector_t) -1) { // if the single-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &inode_disk->single_indirect_data_block_sector_index)) return false; memset (single_indirect_table, -1, BLOCK_SECTOR_SIZE); } else { // if the indirect table exists, then load it block_read_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } // if current block index is not allocated, allocate new sector if(single_indirect_table[block_index] == (block_sector_t) -1) { if (!free_map_allocate (1, §or)) return false; single_indirect_table[block_index] = sector; // update the block which contains single-indirect table block_write_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } } else { // case for double-indirect block_index -= INDIRECT_BLOCK_ENTRIES; if (inode_disk->double_indirect_data_block_sector_index == (block_sector_t) -1) { // if the double-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &inode_disk->double_indirect_data_block_sector_index)) return false; memset (double_indirect_table, -1, BLOCK_SECTOR_SIZE); } else { // if the double-indirect table exists, then load it block_read_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } int double_block_index = block_index/INDIRECT_BLOCK_ENTRIES; if (double_indirect_table[double_block_index] == (block_sector_t) -1) { // if the single-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &double_indirect_table[double_block_index])) return false; // update double-indirect table block_write_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); memset (single_indirect_table, -1, BLOCK_SECTOR_SIZE); // update single-indirect table block_write_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } else { // if single-indirect table exists, then load it block_read_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } // if current block index is not allocated, allocate new sector if(single_indirect_table[block_index - double_block_index*INDIRECT_BLOCK_ENTRIES] == (block_sector_t) -1) { if (!free_map_allocate (1, §or)) return false; single_indirect_table[block_index - double_block_index*INDIRECT_BLOCK_ENTRIES] = sector; // update the block which contains single-indirect table block_write_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } } } // initialize the new sector as zeros block_write_buffer_cache(fs_device, sector, zeros, 0, BLOCK_SECTOR_SIZE, 0); } return true; }
- This crucial new function manages the dynamic allocation of data blocks when a file’s length increases.
inode_create()- This function is re-implemented to leverage
grow_file_length()for allocating the initial data blocks for a newly created file based on its specified length. - After
grow_file_length()successfully allocates the necessary blocks and updates theinode_diskstructure,inode_create()writes this updatedinode_diskto its designated sector on disk using the buffer cache.
Click to see the refined code
bool inode_create (block_sector_t sector, off_t length) { struct inode_disk *disk_inode = NULL; bool success = false; ASSERT (length >= 0); /* If this assertion fails, the inode structure is not exactly one sector in size, and you should fix that. */ ASSERT (sizeof *disk_inode == BLOCK_SECTOR_SIZE); disk_inode = calloc (1, sizeof *disk_inode); if (disk_inode != NULL) { // initialize disk_inode as -1, leading to the maximum number of block_sector_t because it is unsigned type memset (disk_inode, -1, BLOCK_SECTOR_SIZE); disk_inode->length = 0; if (!grow_file_length(disk_inode, disk_inode->length, length)) { free(disk_inode); return false; } disk_inode->magic = INODE_MAGIC; block_write(fs_device, sector, disk_inode); free (disk_inode); success = true; } return success; }
- This function is re-implemented to leverage
inode_write_at()- This function is modified to support file growth during write operations.
- Before writing data, it checks if the write extends beyond the current
inode->data.length.- If an extension is required, it calls
grow_file_length()to dynamically allocate new data blocks before proceeding with the actual data write to the buffer cache.
Click to see the refined code
// other codes if (inode->deny_write_cnt) return 0; lock_acquire(&buffer_cache_lock); if(inode->data.length < offset + size) { lock_release(&buffer_cache_lock); if(!grow_file_length (&inode->data, inode->data.length, offset + size)) exit(-1); lock_acquire(&buffer_cache_lock); block_write_buffer_cache(fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); } while (size > 0) // other codes - If an extension is required, it calls
free_data_blocks()- This new function is responsible for deallocating all disk sectors that belong to a given
inode_diskstructure. - It systematically iterates through the direct data block entries, releasing any allocated sectors.
- It then proceeds to deallocate sectors pointed to by the single-indirect pointer,
- and finally, it recursively deallocates blocks referenced by the double-indirect pointer, including the indirect tables themselves, returning all freed sectors to the free map.
Click to see the refined code
void free_data_blocks (struct inode_disk *inode_disk) { int current_count; for (current_count = 0; current_count < DIRECT_BLOCK_ENTRIES; ++current_count) { if (inode_disk->direct_data_block_table[current_count] == (block_sector_t) -1) break; free_map_release(inode_disk->direct_data_block_table[current_count], 1); } if (inode_disk->single_indirect_data_block_sector_index == (block_sector_t) -1) return; block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (indirect_table[current_count] == (block_sector_t) -1) break; free_map_release(indirect_table[current_count], 1); } free_map_release(inode_disk->single_indirect_data_block_sector_index, 1); if (inode_disk->double_indirect_data_block_sector_index == (block_sector_t) -1) return; block_sector_t double_indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (double_indirect_table[current_count] == (block_sector_t) -1) break; block_read_buffer_cache(fs_device, double_indirect_table[current_count], indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (indirect_table[current_count] == (block_sector_t) -1) break; free_map_release(indirect_table[current_count], 1); } free_map_release(double_indirect_table[current_count], 1); } free_map_release(inode_disk->double_indirect_data_block_sector_index, 1); }
- This new function is responsible for deallocating all disk sectors that belong to a given
inode_close()- This function is re-implemented to ensure proper resource management.
- When an inode is closed and marked for removal (
inode->removed == true), it now callsfree_data_blocks()to deallocate all associated data sectors.
Click to see the refined code
void inode_close (struct inode *inode) { /* Ignore null pointer. */ if (inode == NULL) return; /* Release resources if this was the last opener. */ if (--inode->open_cnt == 0) { /* Remove from inode list and release lock. */ list_remove (&inode->elem); /* Deallocate blocks if removed. */ if (inode->removed) { free_data_blocks(&inode->data); free_map_release(inode->sector, 1); } free (inode); } } - When an inode is closed and marked for removal (
- This function is re-implemented to ensure proper resource management.
Conclusion
- Thanks to these improvements, PintOS files can now dynamically grow, supporting file sizes up to approximately 8.123 MB.
- This significantly enhances the flexibility and utility of the file system.
- With the buffer cache and extensible files now in place, only one major task remains:
- introducing subdirectories, which is the focus of the next section.
Part 3: Subdirectories
Objective
- The objective of this final part is to implement a hierarchical directory structure, enabling the creation and management of subdirectories within the PintOS file system.
Current Problem
- The current PintOS lacks support for hierarchical directories.
- This limitation stems from the absence of dedicated system calls or underlying file system mechanisms to distinguish directories from regular files or to navigate a multi-level directory tree.
- The existing file system assumes a flat structure, making it impossible to organize files into subdirectories.
Click to see the original code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { case SYS_HALT: halt(); break; case SYS_EXIT: exit(current_esp[1]); break; case SYS_EXEC: f->eax = exec(current_esp[1]); break; case SYS_WAIT: f->eax = wait(current_esp[1]); break; case SYS_CREATE: f->eax = create(current_esp[1], current_esp[2]); break; case SYS_REMOVE: f->eax = remove(current_esp[1]); break; case SYS_OPEN: f->eax = open(current_esp[1]); break; case SYS_FILESIZE: f->eax = filesize(current_esp[1]); break; case SYS_READ: f->eax = read(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_WRITE: f->eax = write(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_SEEK: seek(current_esp[1], current_esp[2]); break; case SYS_TELL: f->eax = tell(current_esp[1]); break; case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; case SYS_CHDIR: /* missing! */ break; case SYS_MKDIR: /* missing! */ break; case SYS_READDIR: /* missing! */ break; case SYS_ISDIR: /* missing! */ break; case SYS_INUMBER: /* missing! */ break; default: PANIC("Invalid System Call"); } }
Solution
- The solution transforms the file system into a hierarchical structure, making it possible to create, navigate, and manage subdirectories.
- This involves:
- Distinguishing File Types
- The on-disk inode structure (
struct inode_disk) is modified to include a specific flag that identifies whether an inode represents a directory or a regular file. - This allows the file system to differentiate between them at a fundamental level.
- The on-disk inode structure (
- Per-Thread Current Directory
- Each thread now maintains its own current working directory (
.). - This design enables threads to operate within specific directory contexts, supporting relative path resolution.
- Child threads inherit their parent’s current directory, ensuring a consistent hierarchical context.
- Each thread now maintains its own current working directory (
- New Directory System Calls
- Essential system calls for directory management, such as
chdir,mkdir,readdir,isdir, andinumber, are implemented. - These system calls provide the necessary interface for user programs to interact with the new directory structure.
- Essential system calls for directory management, such as
- Path Parsing Logic
- A new function,
parse_path(), is introduced to handle the complexities of resolving absolute and relative paths within the hierarchical file system. - This function is crucial for all file system operations that involve paths.
- A new function,
- Distinguishing File Types
- To achieve these changes, the implementation requires modifications to key file system components,
- including the
inode_diskstructure, and enhancements to various functions ininode.c,filesys.c,directory.c, andsyscall.c.
- including the
Implementation Details
- The following components have been modified or introduced:
thread.hstruct thread- A new data member,
current_directoryof typestruct dir *, is added to each thread’s structure.- This pointer keeps track of the thread’s current working directory, enabling relative path operations.
Click to see the refined code
// other codes struct dir *current_directory; // other codes
- A new data member,
thread.cinit_thread()- The
current_directorymember of a new thread is initialized toNULL.Click to see the refined code
// other codes list_init(&t->mmap_table); t->current_available_map_id = 0; t->current_directory = NULL; // new code t->parent_thread_pointer = NULL; old_level = intr_disable (); // other codes
- The
thread_create()- When a new thread is created, it now explicitly inherits the
current_directoryfrom its parent thread.- This is achieved by reopening the parent’s directory using
dir_reopen().
Click to see the refined code
// other codes #ifdef USERPROG /* push child process to parent */ list_push_back(&thread_current()->children, &t->childelem); #endif /* Make the child thread inherit the current directory from its parent thread */ if (thread_current()->current_directory) t->current_directory = dir_reopen(thread_current()->current_directory); /* Update pointer to its parent thread */ t->parent_thread_pointer = thread_current(); /* Add to run queue. */ thread_unblock(t); // other codes - This is achieved by reopening the parent’s directory using
- When a new thread is created, it now explicitly inherits the
inode.cstruct inode_disk- This structure is updated to include an
is_directoryflag.- This flag, of type
block_sector_tfor alignment, explicitly indicates whether the inode represents a directory.
- This flag, of type
- As a consequence, the number of direct data block entries (
DIRECT_BLOCK_ENTRIES) is adjusted to accommodate this new flag within the sector.Click to see the refined code
#define DIRECT_BLOCK_ENTRIES 123 /* now it's 123! */ struct inode_disk { off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ block_sector_t is_directory; /* new member! */ block_sector_t direct_data_block_table [DIRECT_BLOCK_ENTRIES]; block_sector_t single_indirect_data_block_sector_index; block_sector_t double_indirect_data_block_sector_index; };
- This structure is updated to include an
inode_create()- This function is modified to accept an additional boolean parameter,
is_directory_given.- This parameter determines whether the newly created inode represents a regular file or a directory, setting the
is_directoryflag accordingly.
- This parameter determines whether the newly created inode represents a regular file or a directory, setting the
- This change necessitates updates to all functions that call
inode_create().- Specifically,
filesys_create(),dir_create(), andfree_map_create()are needed to be updated.
Click to see the refined code
bool inode_create (block_sector_t sector, off_t length, bool is_directory_given) { // same codes disk_inode->magic = INODE_MAGIC; disk_inode->is_directory = is_directory_given; // new code block_write(fs_device, sector, disk_inode); // same codes } - Specifically,
- This function is modified to accept an additional boolean parameter,
is_inode_valid_directory()- A new helper function is introduced to efficiently check if a given inode is a valid, existing directory (i.e., not removed and its
is_directoryflag is set).Click to see the refined code
bool is_inode_valid_directory(const struct inode *inode) { return inode->removed == false && inode->data.is_directory == true; }
- A new helper function is introduced to efficiently check if a given inode is a valid, existing directory (i.e., not removed and its
inode.hModified Declarations- The declaration for
inode_create()is updated to reflect its newis_directory_givenparameter. - The declaration for the newly added
is_inode_valid_directory()function is also included.Click to see the refined code
// other codes off_t inode_length (const struct inode *); bool inode_create (block_sector_t, off_t, bool); // modified! bool is_inode_valid_directory(const struct inode *inode); // new one!
- The declaration for
filesys.cfilesys_init()- During file system initialization, this function now sets the main thread’s
current_directoryto the root directory.- To enable this,
thread.his included.
Click to see the refined code
#include "threads/thread.h" // other codes void filesys_init (bool format) { // other codes free_map_open(); // Initialize current directory of main thread struct dir *root_dir = dir_open_root(); thread_current()->current_directory = root_dir; dir_add (root_dir, ".", ROOT_DIR_SECTOR); } - To enable this,
- During file system initialization, this function now sets the main thread’s
parse_path()- This crucial new function takes an
original_pathand afile_namebuffer. - It traverses the directory tree, starting from either the root or the current thread’s directory, resolves the path components,
- and returns a pointer to the target directory while extracting the final file or directory name.
- It also handles cases where path components are invalid or refer to non-directory inodes.
PATH_MAX_LENGTHis defined infilesys.hto manage path buffer sizes.Click to see the refined code
struct dir * parse_path (const char *original_path, char *file_name) { struct dir *dir = NULL; if (!original_path || !file_name) return NULL; if (strlen(original_path) == 0) return NULL; char path[PATH_MAX_LENGTH + 1]; strlcpy(path, original_path, PATH_MAX_LENGTH); if (path[0] == '/') dir = dir_open_root (); else dir = dir_reopen(thread_current()->current_directory); if(is_inode_valid_directory(dir_get_inode(dir)) == false) return NULL; char *token, *next_token, *save_ptr; token = strtok_r(path, "/", &save_ptr); next_token = strtok_r(NULL, "/", &save_ptr); if(token == NULL) { strlcpy(file_name, ".", PATH_MAX_LENGTH); return dir; } while(token && next_token) { struct inode *inode = NULL; if(!dir_lookup (dir, token, &inode)) { dir_close(dir); return NULL; } if (is_inode_valid_directory(inode) == false) { dir_close(dir); return NULL; } dir_close(dir); dir = dir_open(inode); token = next_token; next_token = strtok_r(NULL, "/", &save_ptr); } strlcpy(file_name, token, PATH_MAX_LENGTH); return dir; }
- This crucial new function takes an
filesys_create()- This function is updated to pass
falseas theis_directory_givenflag when callinginode_create(), ensuring it is correctly marked as such on disk.Click to see the refined code
bool filesys_create (const char *path, off_t initial_size) { block_sector_t inode_sector = 0; char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = (dir != NULL && free_map_allocate (1, &inode_sector) && inode_create (inode_sector, initial_size, false) && dir_add (dir, name, inode_sector)); if (!success && inode_sector != 0) free_map_release (inode_sector, 1); dir_close (dir); return success; }
- This function is updated to pass
filesys_create_dir()- A new function that handles the creation of directories.
- It uses
parse_path()to find the parent directory and then callsdir_create()anddir_add()to allocate and register the new directory’s inode.- It also initializes the special
.(current directory) and..(parent directory) entries within the new directory.
Click to see the refined code
/* Creates a directory */ bool filesys_create_dir(const char *path) { block_sector_t inode_sector = 0; char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = (dir != NULL && free_map_allocate (1, &inode_sector) && dir_create (inode_sector, 16) && dir_add (dir, name, inode_sector)); if(!success && inode_sector != 0) free_map_release (inode_sector, 1); if(success) { struct dir *new_dir = dir_open(inode_open(inode_sector)); dir_add (new_dir, ".", inode_sector); dir_add (new_dir, "..", inode_get_inumber(dir_get_inode(dir))); dir_close (new_dir); } dir_close (dir); return success; } - It also initializes the special
filesys_open()- This function is modified to use
parse_path()to locate the inode corresponding to the given path.Click to see the refined code
struct file * filesys_open(const char *path) { char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); struct inode *inode = NULL; if(dir != NULL) dir_lookup(dir, name, &inode); dir_close(dir); return file_open(inode); }
- This function is modified to use
filesys_remove()- This function is updated to use
parse_path()for locating the target entry. - It includes logic to prevent the removal of non-empty directories, ensuring that only empty directories (containing just
.and..) can be removed.Click to see the refined code
bool filesys_remove (const char *path) { char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = false; if(dir != NULL) { struct inode *target_inode = NULL; if(dir_lookup(dir, name, &target_inode) == false) return false; if(is_inode_valid_directory(target_inode) == false) { inode_close(target_inode); success = dir_remove(dir, name); } else { char temp_name[PATH_MAX_LENGTH + 1]; struct dir *dir_to_check = dir_open(target_inode); char previous_name[PATH_MAX_LENGTH + 1]; for(int i = 0; i < 3; ++i) { dir_readdir(dir_to_check, temp_name); if(strcmp(temp_name, "..") == 0 && strcmp(previous_name, temp_name) == 0) { success = true; break; } strlcpy(previous_name, temp_name, sizeof(previous_name)); } dir_close(dir_to_check); // remove directory only it's empty if(success) success = dir_remove(dir, name); } } dir_close(dir); return success; }
- This function is updated to use
filesys.hNew Declarations and Constants- Declarations for
parse_path()andfilesys_create_dir()are added. PATH_MAX_LENGTHis defined as128to set the maximum length for file paths.Click to see the refined code
#define PATH_MAX_LENGTH 128 // other codes struct dir *parse_path(const char *original_path, char *file_name); bool filesys_create_dir(const char *path);
- Declarations for
directory.cdir_create()- This function is modified to pass
trueas theis_directory_givenflag toinode_create(), ensuring that new directory inodes are correctly identified.Click to see the refined code
bool dir_create (block_sector_t sector, size_t entry_cnt) { return inode_create (sector, entry_cnt * sizeof (struct dir_entry), true); }
- This function is modified to pass
directory.hNAME_MAX- The maximum length of a file name (
NAME_MAX) is increased to 26 characters.- This adjustment ensures that each disk block can accommodate 16 directory entries, optimizing storage for directory contents.
Click to see the refined code
#define NAME_MAX 26
- The maximum length of a file name (
free-map.c- ``free_map_create()`
- This function is updated to pass
falseas theis_directory_givenflag toinode_create()when establishing the free map inode, correctly marking it as a non-directory file.Click to see the refined code
void free_map_create (void) { /* Create inode. */ if (!inode_create (FREE_MAP_SECTOR, bitmap_file_size (free_map), false)) // modified PANIC ("free map creation failed"); // other codes }
- This function is updated to pass
- ``free_map_create()`
syscall.cHeader Inclusionfilesys.his now included instead ofvaddr.hto grant access to the newly defined file system interfaces and structures.Click to see the refined code
#include "vm/page.h" #include "filesys/filesys.h" //#include "threads/vaddr.h" // other codes
chdir()- This new function is the system call to change the current working directory of the calling process.
- It uses
parse_path()to resolve the new directory and, if successful, updates the thread’scurrent_directorypointer.Click to see the refined code
bool chdir(const char *path_original) { char path[PATH_MAX_LENGTH + 1]; strlcpy(path, path_original, PATH_MAX_LENGTH); strlcat(path, "/0", PATH_MAX_LENGTH); char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); if(!dir) return false; dir_close(thread_current()->current_directory); thread_current()->current_directory = dir; return true; }
mkdir()- This new function is the system call to create a new directory at the specified path by calling
filesys_create_dir().Click to see the refined code
bool mkdir(const char *dir) { return filesys_create_dir(dir); }
- This new function is the system call to create a new directory at the specified path by calling
readdir()- This new function is the system call to read directory entries from a file descriptor representing a directory.
- It iterates through the directory, returning each entry’s name.
- It returns
falseif there’s no such entry.
- It returns
- It specifically filters out the special
.and..entries to prevent infinite loops or redundant listings.
Click to see the refined code
bool readdir(int fd, char *name) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); struct inode *target_inode = file_get_inode(target_file); if(target_inode == NULL || is_inode_valid_directory(target_inode) == false) return false; struct dir *dir = dir_open(target_inode); if(dir == NULL) return false; bool was_parent_previously = false; if(strcmp(name, "..") == 0) was_parent_previously = true; int current_count; bool result = true; off_t *pos = (off_t *)target_file + 1; for(current_count = 0; current_count <= *pos && result; ++current_count) result = dir_readdir(dir, name); if(current_count <= *pos == false) ++(*pos); if(was_parent_previously && strcmp(name, "..") == 0) return false; if(strcmp(name, ".") == 0 || strcmp(name, "..") == 0) return readdir(fd, name); return result; } - It iterates through the directory, returning each entry’s name.
- This new function is the system call to read directory entries from a file descriptor representing a directory.
isdir()- This new function is the system call to check if a given file descriptor refers to a directory by using
is_inode_valid_directory().Click to see the refined code
bool isdir(int fd) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); return is_inode_valid_directory(file_get_inode(target_file)); }
- This new function is the system call to check if a given file descriptor refers to a directory by using
inumber()- This new function is the system call to retrieve the inode number (sector index) associated with a given file descriptor.
Click to see the refined code
block_sector_t inumber(int fd) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); return inode_get_inumber(file_get_inode(target_file)); }
- This new function is the system call to retrieve the inode number (sector index) associated with a given file descriptor.
write()- The
write()system call is updated to prohibit writing operations to directory file descriptors.- If an attempt is made to write to a directory, it calls
exit(-1).
Click to see the refined code
// other codes if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL || is_inode_valid_directory(file_get_inode(thread_current()->fd_table[fd]))) // new condition! { exit(-1); } lock_acquire(&filesys_lock); // other codes - If an attempt is made to write to a directory, it calls
- The
syscall_handler()- The main system call handler is modified to dispatch calls for the newly implemented directory-related system calls (
SYS_CHDIR,SYS_MKDIR,SYS_READDIR,SYS_ISDIR,SYS_INUMBER) to their respective functions.Click to see the refined code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { case SYS_HALT: halt(); break; case SYS_EXIT: exit(current_esp[1]); break; case SYS_EXEC: f->eax = exec(current_esp[1]); break; case SYS_WAIT: f->eax = wait(current_esp[1]); break; case SYS_CREATE: f->eax = create(current_esp[1], current_esp[2]); break; case SYS_REMOVE: f->eax = remove(current_esp[1]); break; case SYS_OPEN: f->eax = open(current_esp[1]); break; case SYS_FILESIZE: f->eax = filesize(current_esp[1]); break; case SYS_READ: f->eax = read(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_WRITE: f->eax = write(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_SEEK: seek(current_esp[1], current_esp[2]); break; case SYS_TELL: f->eax = tell(current_esp[1]); break; case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; case SYS_CHDIR: f->eax = chdir(current_esp[1]); break; case SYS_MKDIR: f->eax = mkdir(current_esp[1]); break; case SYS_READDIR: f->eax = readdir(current_esp[1], current_esp[2]); break; case SYS_ISDIR: f->eax = isdir(current_esp[1]); break; case SYS_INUMBER: f->eax = inumber(current_esp[1]); break; default: PANIC("Invalid System Call"); } }
- The main system call handler is modified to dispatch calls for the newly implemented directory-related system calls (
Conclusion
- With the implementation of subdirectories, PintOS now supports a fully hierarchical file system, addressing all the objectives for this final project.
- This completes a robust and functional file system, enabling flexible data organization and management.
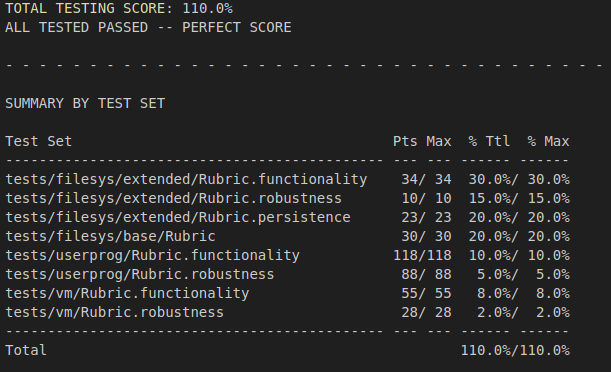
Improved Grade
Final Thoughts
- This project significantly upgraded the basic PintOS file system into a more robust, efficient, and user-friendly component.
- This has been achieved by integrating a buffer cache to dramatically improve I/O performance through intelligent data caching and by redesigning the file structure to support extensible files, allowing them to grow dynamically to much larger sizes.
- Finally, the implementation of subdirectories enabled a hierarchical and intuitive organization of files, not only enhancing user experience but also laying the groundwork for future advanced features.
- Collectively, these improvements demonstrate a deep understanding of core file system mechanics and the intricate processes involved in developing a sophisticated operating system component.
Github Repository
- You can find the actual files I modified for PintOS at my GitHub repository: PintOS
Leave a comment