Project 3: Memory
메모리 (Memory)
- 세 번째 프로젝트는 다음을 통해 PintOS의 메모리 관리를 획기적으로 개선합니다:
- 각 프로세스에 대한 보조 페이지 테이블 (supplemental page table) 구현.
- 요구 페이징 (demand paging) 도입을 통한 페이지 폴트 (page fault) 효과적 처리 및 동적 스택 확장 (dynamic stack growth) 지원.
- 프로세스 메모리 접근을 최적화하기 위한 메모리 매핑 (memory mapping) 기능 추가.
-
아래에서는 각 구성 요소에 대한 목표, 도전 과제, 해결책, 구현 내용을 간략하게 설명했습니다.
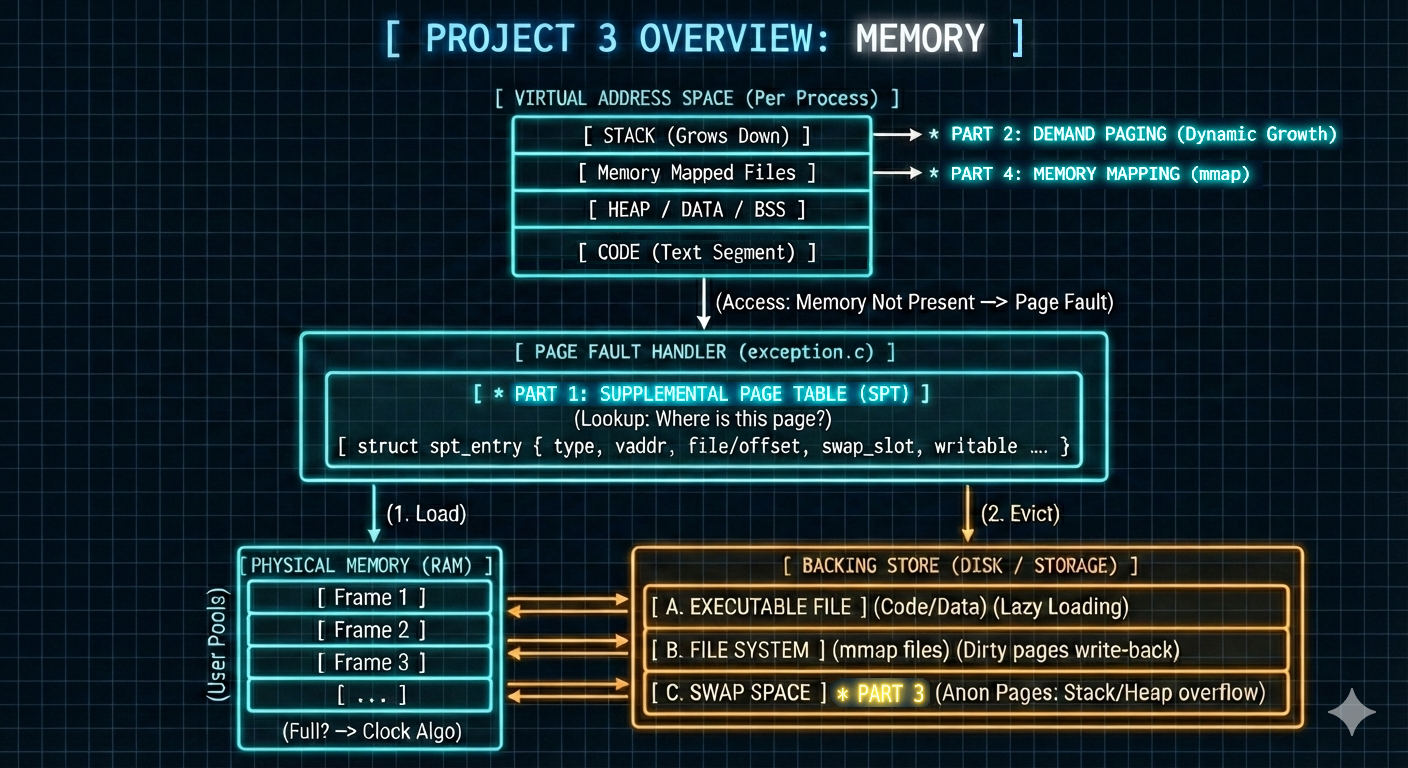
Part 1: 보조 페이지 테이블 (Supplemental Page Table)
목표
- 이 초기 단계의 주요 목표는 PintOS의 각 프로세스에 대한 보조 페이지 테이블 (SPT)을 구현하는 것입니다.
- 이 근본적인 변화는 요구 페이징 (demand paging)을 가능하게 하는 데 필수적입니다. 요구 페이징은 프로세스 시작 시 추측적으로 할당하는 대신, 프로세스에 의해 실제로 접근될 때만 물리 메모리 페이지가 할당되는 메모리 관리 기법입니다.
- 이 접근 방식은 메모리 활용도를 크게 최적화하고 시스템의 확장성을 향상시키는 것을 목표로 합니다.
기존 문제
- 기존의
load_segment()함수는 실행 가능한 세그먼트 (executable segment)를 로드하는 역할을 했습니다. - 이 원래 구현의 주요 비효율성은 선제적 할당 전략 (eager allocation strategy)이었습니다:
- 프로세스가 로드되는 순간, 해당 페이지들이 즉시 사용될지 여부와 관계없이 각 세그먼트에 필요한 모든 물리 페이지를 할당했습니다.
-
이러한 선행 할당 (pre-allocation)은 특히 코드나 데이터 세그먼트의 일부만이 특정 시점에 활발하게 사용되는 대형 프로그램의 경우, 상당하고 종종 불필요한 물리 메모리 소모를 초래할 수 있었습니다.
Click to see the original code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT (pg_ofs (upage) == 0); ASSERT (ofs % PGSIZE == 0); file_seek (file, ofs); while (read_bytes > 0 || zero_bytes > 0) { /* Calculate how to fill this page. We will read PAGE_READ_BYTES bytes from FILE and zero the final PAGE_ZERO_BYTES bytes. */ size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; /* Get a page of memory. */ uint8_t *kpage = palloc_get_page (PAL_USER); if (kpage == NULL) return false; /* Load this page. */ if (file_read (file, kpage, page_read_bytes) != (int) page_read_bytes) { palloc_free_page (kpage); return false; } memset (kpage + page_read_bytes, 0, page_zero_bytes); /* Add the page to the process's address space. */ if (!install_page (upage, kpage, writable)) { palloc_free_page (kpage); return false; } /* Advance. */ read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; upage += PGSIZE; } return true; }
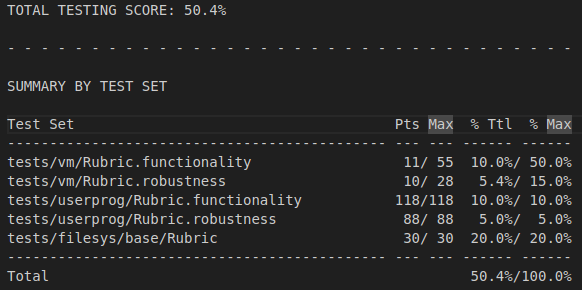
원래 점수
해결책
- 저의 해결책은
load_segment()가 작동하는 방식에 근본적인 변화를 주었습니다. - 재구현된
load_segment()는 물리 메모리 페이지를 직접 요청하고 매핑하는 대신, 새로 도입된 보조 페이지 테이블에 엔트리 (entries,struct spt_entry)를 채워 넣습니다.- 이 엔트리들은 플레이스홀더 (placeholder) 또는 디스크립터 (descriptor) 역할을 하며, 해당 페이지가 프로세스에 의해 실제로 접근될 때 물리 페이지를 나중에 로드하는 데 필요한 모든 메타데이터를 포함합니다.
- 이러한 지연 할당 전략 (deferred allocation strategy)은 프로세스의 초기 메모리 사용량 (memory footprint)을 획기적으로 줄여줍니다.
- 이를 용이하게 하기 위해, 저는
struct spt_entry를 설계하고 구현했습니다.- 이 구조체는 가상 페이지에 필요한 모든 정보를 캡슐화하도록 신중하게 제작되었습니다.
-
이
spt_entry인스턴스들은 보조 페이지 테이블의 근간을 형성하며, 온디맨드 페이지 로딩 (on-demand page loading)에 필요한 컨텍스트를 제공합니다.
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
page.hstruct spt_entrypage.h는 이제struct spt_entry에 대한 정의를 포함합니다.- 이 새로운 구조체는 가상 페이지에 대한 포괄적인 정보를 캡처합니다. 해당 정보는 다음과 같습니다:
- 페이지의 유형 (type)
- 코드 세그먼트 (code segment)를 위한
SPT_BIN - 스택 (stack), 힙 (heap) 세그먼트 또는 기타 유형을 위한
SPT_ANON - 메모리 매핑된 파일 (memory-mapped files)을 위한
SPT_FILE
- 코드 세그먼트 (code segment)를 위한
- 스택 페이지를 위한 플래그 (
is_stack), - 가상 주소 (
vaddr), - 제로 패딩 (zero-padding) 크기 (
zero_bytes), - 그리고 중요한 파일 관련 메타데이터 (
file,read_bytes,offset,writable).
- 페이지의 유형 (type)
- 또한, 이 구조체는 SPT인
struct list객체에 포함될 수 있도록list_elem을 포함합니다.
Click to see the refined code
enum page_type { SPT_BIN, /* code segment */ SPT_ANON, /* stack, heap or anonymous */ SPT_FILE /* file-backed page */ }; /* spt_entry for spt in each thread */ struct spt_entry { enum page_type type; // type of page bool is_stack; // flag for stack growth void *vaddr; // virtual page int zero_bytes; // padding info // these are necessary to load the actual file from disk struct file *file; int read_bytes, offset; bool writable; struct list_elem sptelem; // List element for page table };
thread.hstruct threadstruct thread에 새로운 데이터 멤버인supplemental_page_table이 추가되었습니다.- 이 멤버는 해당 스레드 (프로세스)에 대한 모든
spt_entry인스턴스를 담는struct list이며, 프로세스별 보조 페이지 테이블을 효과적으로 구성합니다.
- 이 멤버는 해당 스레드 (프로세스)에 대한 모든
- 추가적으로,
struct thread는 이제 두 개의 다른 데이터 멤버를 포함합니다:current_stack_top: 스택 확장 목적으로 동적으로 변하는 스택의 최상단 (top)을 추적합니다.- 이는
setup_stack()에서 초기화됩니다.
- 이는
initial_code_segment: 실행 파일의 코드 세그먼트 (code segment)의 기본 가상 주소 (base virtual address)를 저장하여, 메모리 접근 경계 (memory access boundaries)를 검증하는 데 유용합니다.- 이는
start_process()에서 초기화됩니다.
- 이는
Click to see the refined code
struct thread { // other codes struct list supplemental_page_table; /* supplemental page table */ void *current_stack_top; /* current stack top */ void *initial_code_segment; /* address of code segment */ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
process.cstart_process()start_process()는 현재 스레드에 대한supplemental_page_table리스트를 초기화하도록 수정되었습니다.- 또한, 세그먼트가 로드되기 전에
initial_code_segment를NULL로 설정합니다. - 이는 새로운 프로세스의 가상 메모리 관리를 위해 깨끗한 상태 (clean state)를 보장합니다.
Click to see the refined code
static void start_process (void *file_name_) { // other codes /* Initialize interrupt frame and load executable. */ struct intr_frame if_; bool success; /* Initialize the set of spt_entries */ struct thread *current_thread = thread_current(); list_init(¤t_thread->supplemental_page_table); current_thread->initial_code_segment = NULL; // other codes }
process_exit()- 메모리 누수 (memory leaks)를 방지하고 적절한 자원 정리 (resource cleanup)를 보장하기 위해,
process_exit()가 강화되었습니다. - 이 함수는 스레드의
supplemental_page_table을 순회합니다.- 각
spt_entry에 대해, 엔트리 자체와 관련된 메모리를 할당 해제합니다 (free()사용).
- 각
- 이는 프로세스가 종료될 때 보조 페이지 테이블을 효과적으로 해체 (tear down)하는 역할을 수행합니다.
Click to see the refined code
void process_exit (void) { file_close(cur->current_running_file); /* deallocate supplemental page table */ for(struct list_elem *current_element = list_begin(&cur->supplemental_page_table), *end_element = list_end(&cur->supplemental_page_table), *next_element ; current_element != end_element;) { struct spt_entry *target_entry = list_entry(current_element, struct spt_entry, sptelem); next_element = list_next(current_element); list_remove(current_element); free(target_entry); current_element = next_element; } // other code }
- 메모리 누수 (memory leaks)를 방지하고 적절한 자원 정리 (resource cleanup)를 보장하기 위해,
load_segment()- 이 함수는 할당 전략에서 가장 중요한 변화를 나타냅니다.
- 수정된
load_segment()는 더 이상palloc_get_page()나install_page()를 직접 호출하지 않습니다.- 대신, 세그먼트의 페이지 크기 청크 (page-sized chunk) 각각에 대해 새로운
spt_entry를 동적으로 할당합니다.
- 대신, 세그먼트의 페이지 크기 청크 (page-sized chunk) 각각에 대해 새로운
- 이 엔트리에 필요한 세부 정보 (가상 주소, 파일 정보, 쓰기 가능 여부)를 채워 넣습니다.
- 그런 다음, 이
spt_entry를 현재 스레드의supplemental_page_table에 추가합니다.
- 그런 다음, 이
- 또한, 처리 중인 세그먼트가 첫 번째 코드 세그먼트인 경우 스레드의
initial_code_segment를 설정합니다.Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT (pg_ofs (upage) == 0); ASSERT (ofs % PGSIZE == 0); file_seek (file, ofs); struct thread *current_thread = thread_current(); while (read_bytes > 0 || zero_bytes > 0) { /* Calculate how to fill this page. We will read PAGE_READ_BYTES bytes from FILE and zero the final PAGE_ZERO_BYTES bytes. */ size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; struct spt_entry *new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) return false; new_entry->type = SPT_BIN; new_entry->is_stack = false; new_entry->vaddr = upage; if (current_thread->initial_code_segment == NULL) current_thread->initial_code_segment = upage; new_entry->zero_bytes = page_zero_bytes; new_entry->file = file; new_entry->read_bytes = page_read_bytes; new_entry->offset = ofs; new_entry->writable = writable; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); /* Advance. */ read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; upage += PGSIZE; ofs += PGSIZE; } return true; }
결론
- 이러한 수정 사항들은 요구 페이징 (demand paging)을 위한 기반을 성공적으로 마련했습니다.
- 이들은 보조 페이지 테이블을 도입하고 프로그램 세그먼트가 로드되는 방식을 근본적으로 변경합니다.
- 물리 페이지 할당을 지연함으로써, 이 구현은 프로세스당 초기 메모리 사용량을 크게 줄입니다.
- 하지만, 페이지 폴트 (page fault)를 처리하는 능력은 프로젝트의 후속 부분에서 다루어져야 합니다.
Part 2: 요구 페이징 (Demand Paging)
목표
- 이 부분의 핵심 목표는 PintOS 내에 요구 페이징 (demand paging)을 구현하는 데 중점을 둡니다.
- 이 메커니즘은 프로세스가 물리 메모리 페이지에 접근을 시도할 때만 해당 페이지가 할당되도록 보장합니다.
- 요구 페이징의 중요한 이점은 동적 스택 확장 (dynamic stack growth)을 가능하게 한다는 것입니다.
- 이를 통해 스택이 필요에 따라 자동으로 확장될 수 있어, 메모리 효율성과 유연성이 향상됩니다.
기존 문제
- 기존의
page_fault()함수는 페이지 폴트가 발생했을 때 단순히kill()을 호출하여 프로세스를 종료시켰습니다. -
이러한 설계는 어떠한 형태의 동적 메모리 할당, 효율적인 메모리 관리, 또는 유연한 스택 사용을 방지했습니다.
Click to see the original code
static void page_fault (struct intr_frame *f) { bool not_present; /* True: not-present page, false: writing r/o page. */ bool write; /* True: access was write, false: access was read. */ bool user; /* True: access by user, false: access by kernel. */ void *fault_addr; /* Fault address. */ /* Obtain faulting address, the virtual address that was accessed to cause the fault. It may point to code or to data. It is not necessarily the address of the instruction that caused the fault (that's f->eip). See [IA32-v2a] "MOV--Move to/from Control Registers" and [IA32-v3a] 5.15 "Interrupt 14--Page Fault Exception (#PF)". */ asm ("movl %%cr2, %0" : "=r" (fault_addr)); /* Turn interrupts back on (they were only off so that we could be assured of reading CR2 before it changed). */ intr_enable (); /* Count page faults. */ page_fault_cnt++; /* Determine cause. */ not_present = (f->error_code & PF_P) == 0; write = (f->error_code & PF_W) != 0; user = (f->error_code & PF_U) != 0; kill (f); }
해결책
- 페이지 폴트를 처리하고 스택 확장을 지원하기 위해, 저는 다음과 같은 주요 변경 사항을 적용했습니다:
setup_stack()재구현:- 이 함수는 이제 현재 스레드의
current_stack_top을 초기화하고, 보조 페이지 테이블 (spt_entry)에 초기 스택 페이지를 설정합니다. - 이
spt_entry는 스택 확장을 관리하는 데 매우 중요합니다.
- 이 함수는 이제 현재 스레드의
handle_page_fault()도입:- 이 새로운 함수는 페이지 폴트를 해결하는 전용 기능을 담당합니다.
- 이는
spt_entry의 정보를 기반으로 필요한 물리 페이지를 할당하고, 필요한 경우 디스크에서 데이터를 로드합니다. - 현재로서는 메모리 할당이 실패하면 프로세스가 종료됩니다. (페이지 스와핑 (page swapping)은 이후 단계에서 다루어질 예정이기 때문입니다.)
page_fault()수정:- 페이지 폴트가 발생했을 때 프로세스를 즉시 종료하는 대신,
page_fault()는 이제handle_page_fault()를 호출하여 폴트를 해결합니다. - 또한, 스택 확장을 위한 로직을 포함하여 스택이 최대 $8 \text{MB}$까지 확장될 수 있도록 허용합니다.- 폴트 주소 (fault address)가 스택 포인터 (
f->esp)로부터 $32$ 바이트 이내에 있다면,- 스택 확장이 허용됩니다.
- 폴트 주소가 유효하지 않거나, 허용된 범위를 벗어나거나, 최대 스택 크기를 초과하는 경우,
- 해당 스레드는 종료됩니다.
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
process.csetup_stack()- 현재 스레드의
current_stack_top을 초기화합니다. - 또한, 스레드의 보조 페이지 테이블 내에 초기 스택 페이지를 위한
spt_entry를 생성합니다.
Click to see the refined code
static bool setup_stack (void **esp) { uint8_t *kpage; bool success = false; struct thread *current_thread = thread_current(); current_thread->current_stack_top = ((uint8_t *) PHYS_BASE) - PGSIZE; kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage != NULL) { success = install_page (current_thread->current_stack_top, kpage, true); if (success) *esp = PHYS_BASE; else palloc_free_page (kpage); } // update supplemental page table struct spt_entry *new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) return false; new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); return success; }- 현재 스레드의
install_page()- 저는
install_page()의static지정자 (modifier)를 제거하여 수정했습니다.- 이렇게 하여 이 함수가
process.c에 정의되어 있음에도 불구하고, 호출이 필요한page.c에서 접근 가능하도록 만들었습니다.
Click to see the refined code
bool install_page (void *upage, void *kpage, bool writable) { struct thread *t = thread_current (); /* Verify that there's not already a page at that virtual address, then map our page there. */ return (pagedir_get_page (t->pagedir, upage) == NULL && pagedir_set_page (t->pagedir, upage, kpage, writable)); } - 이렇게 하여 이 함수가
- 저는
page.chandle_page_fault()- 이 새로 생성된 함수는 실제 페이지 로딩 프로세스를 조정 (orchestrate)합니다.
- 이 함수는 새로운 물리 페이지를 획득하려고 시도합니다.
- 성공할 경우, 해당
spt_entry에서 페이지의 유형 (바이너리 세그먼트, 익명, 또는 파일 지원)을 확인합니다.- 파일 지원 (file-backed) 페이지의 경우,
filesys_lock을 획득하고 해제함으로써 적절한 파일 시스템 동기화를 보장하며 디스크에서 데이터를 읽습니다.
- 다른 유형의 경우,
- 새로 할당된 페이지로 진행합니다.
- 마지막으로,
install_page()를 사용하여 할당된 물리 페이지를 프로세스의 가상 주소에 매핑 (map)합니다.
- 파일 지원 (file-backed) 페이지의 경우,
- 여기서 중요한 점은 메모리 할당이 실패할 경우, 현재 함수는 오류를 반환하며 프로세스 종료로 이어진다는 것입니다.
- 이를 해결하기 위해 페이지 스와핑 (page swapping)이 필요합니다.
- 이 기능은 다음 부분에서 구현될 예정입니다.
Click to see the refined code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage == NULL) { // if there's no space, terminate the process for now // page swap is needed return false; } // load the data from disk bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); if(target_spt_entry->type != SPT_ANON) { // if the page is not stack nor heap, then read from the disk if(file_read_at(target_spt_entry->file, kpage, target_spt_entry->read_bytes, target_spt_entry->offset) != target_spt_entry->read_bytes) { palloc_free_page (kpage); lock_release(&filesys_lock); return false; } } else { // if the page is stack or heap, then read from swap space if needed // but skip this for now ; } if(is_lock_already_owned == false) lock_release(&filesys_lock); // update page table if (!install_page (target_spt_entry->vaddr, kpage, target_spt_entry->writable)) { palloc_free_page (kpage); return false; } return true; }
exception.cpage_fault()- 이 수정된 인터럽트 핸들러 (interrupt handler)는 이제 폴트 발생 주소 (faulting address)에 대한 초기 유효성 검사를 수행하며, 진정한 유효하지 않은 메모리 접근에 대해서는 프로세스를 종료시킵니다.
- 예: 사용자 모드에서의 커널 주소 공간 접근, 또는 프로세스의 합법적인 가상 주소 범위 밖의 메모리 접근 시도.
- 그런 다음, 스레드의 보조 페이지 테이블에서 폴트 발생 주소에 해당하는 엔트리를 검색합니다.
- 일치하는 엔트리가 발견되면,
kill()대신handle_page_fault()를 호출하여 페이지를 로드합니다.
- 일치하는 엔트리가 발견되면,
- 기존의
spt_entry가 발견되지 않으면,page_fault()는 해당 접근이 스택을 확장하려는 합법적인 시도인지 확인합니다.- 폴트 발생 주소와 현재 스택 포인터 (
f->esp) 사이의 거리를 고려합니다.pusha테스트가 스택에 $32$ 바이트를 푸시하기 때문에, 최대 $32$ 바이트의 여유 공간이 허용된다는 점은 주목할 만합니다.- 또한, 스택이 미리 정의된
MAX_STACK_SIZE를 초과하지 않는지 확인합니다.
- 이러한 조건들이 충족되면, 필요한 만큼 스택을 아래로 확장하면서 보조 페이지 테이블에 새로운 익명 페이지 엔트리 (anonymous page entries)를 동적으로 생성하고,
handle_page_fault()를 통해 이 새로운 페이지 폴트를 해결합니다.
- 폴트 발생 주소와 현재 스택 포인터 (
- 이 유효한 시나리오들에 해당하지 않는 모든 페이지 폴트는
exit(-1)을 호출하여 프로세스 종료로 이어집니다.
Click to see the refined code
#define MAX_STACK_SIZE (8 * 1024 * 1024) // 8MB // other codes static void page_fault (struct intr_frame *f) { // other codes user = (f->error_code & PF_U) != 0; struct thread *current_thread = thread_current(); // Check if the page fault is due to an access violation or invalid memory reference. // If the address is not a valid user virtual address or falls outside the allowed range, // the process is terminated. if(not_present == false || is_user_vaddr(fault_addr) == false || fault_addr < current_thread->initial_code_segment || fault_addr >= PHYS_BASE) exit(-1); // handle page demanding struct spt_entry *target_spt_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table), *end_element = list_end(¤t_thread->supplemental_page_table); current_element != end_element; current_element = list_next(current_element)) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } // handle stack growth // check whether the current attempt is valid for stack growth by comparing the difference between f->esp and fault_addr to 32 bytes. // 32 bytes are chosen due to the pusha test, which pushes 32 bytes. // if the distance is farther than this, terminate the process. // limit the maximum stack growth to MAX_STACK_SIZE (8MB). if(f->esp - fault_addr <= 32 && PHYS_BASE - fault_addr <= MAX_STACK_SIZE) { struct spt_entry *new_entry = NULL; do { // prepare for next stack current_thread->current_stack_top -= PGSIZE; new_entry = malloc(sizeof(struct spt_entry)); if(new_entry == NULL) exit(-1); new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; new_entry->slot_index = -1; new_entry->is_immortal = false; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); } while(current_thread->current_stack_top > fault_addr); if(handle_page_fault(new_entry)) return; } exit(-1); }- 이 수정된 인터럽트 핸들러 (interrupt handler)는 이제 폴트 발생 주소 (faulting address)에 대한 초기 유효성 검사를 수행하며, 진정한 유효하지 않은 메모리 접근에 대해서는 프로세스를 종료시킵니다.
결론
- PintOS는 이제 동적 스택 확장 기능을 갖춘 기본적인 요구 페이징을 특징으로 하며, 메모리 효율성을 개선했습니다.
- 하지만, 여전히 충분한 물리 메모리가 있다고 가정합니다.
- 메모리가 고갈되었을 때 덜 사용되는 페이지를 디스크로 이동시키는 페이지 스와핑 (page swapping) 메커니즘 없이는 프로세스가 종료될 것입니다.
- 다음 단계는 메모리 압박 (memory pressure) 하에서 발생하는 충돌을 방지하고 사용 가능한 RAM보다 더 많은 프로세스를 허용하기 위해 페이지 스와핑을 구현하는 것입니다.
Part 3: 페이지 스와핑 (Page Swap)
목표
- 이 섹션의 목표는 PintOS에서 페이지 스와핑 (page swapping)을 구현하는 데 중점을 둡니다.
- 이 기능은 다음을 위해 필수적입니다:
- 물리적 RAM이 부족해질 때 운영 체제가 메모리를 효과적으로 관리할 수 있도록 지원.
- 메모리 고갈로 인한 프로세스 종료 방지.
기존 문제
- 현재의
handle_page_fault()함수는 요구 페이징 (demand paging)은 가능하지만, 새로운 물리 페이지 할당에 실패할 경우 여전히 프로세스를 종료시켰습니다. -
이러한 갑작스러운 종료는 시스템에 사용 가능한 물리 메모리가 고갈되었을 때 발생하며, 이는 높은 메모리 압력 하에서 견고한 작동 (robust operation)을 위한 메모리 관리의 핵심적인 격차를 나타냅니다.
Click to see the original code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); if (kpage == NULL) { // if there's no space, terminate the process for now // page swap is needed return false; } // other codes }
해결책
- 저의 해결책은 페이지 스와핑 메커니즘을 도입하여 메모리 고갈 문제를 해결합니다:
handle_page_fault()수정:- 이 함수는 물리 메모리 할당 실패에 지능적으로 대응하도록 강화되었습니다.
- 프로세스를 즉시 종료하는 대신, 이제
evict_page()를 호출하여 메모리를 확보하려고 시도합니다.
evict_page()구현:- 이 새로운 함수는 물리 메모리에서 희생 페이지 (victim page)를 선택하고, 수정된 경우 (modified) 그 내용을 스와프 공간 (swap space)에 기록한 다음, 물리 프레임 (physical frame)을 해제하는 역할을 담당합니다.
- 희생 페이지 선택 (Victim Page Selection):
- 어떤 페이지를 축출 (evict)할지 선택하기 위해,
evict_page()는pick_victim_page()에 의존합니다. - 이 함수는 일반적으로 사용되는 페이지 교체 정책인 클럭 알고리즘 (Clock Algorithm)을 구현합니다.
- 클럭 알고리즘은 각 페이지와 연결된 접근 비트 (accessed bit)를 확인하여 최소 최근 사용 (Least Recently Used, LRU) 정책을 효율적으로 근사화합니다.
- 비트가 설정되어 있으면, 지우고 “클럭 핸드” (clock hand)를 전진시킵니다.
- 비트가 지워져 있으면, 해당 페이지가 희생 페이지로 선택됩니다.
- 어떤 페이지를 축출 (evict)할지 선택하기 위해,
- 전역 스와프 공간 관리 (Global Swap Space Management):
- 페이지 스와핑을 지원하기 위해, 전용 스와프 공간이 설정되었습니다.
- 이 스와프 공간은 전역적으로 설계되었으며, 이는 모든 프로세스가 공유한다는 의미입니다.
- 저는 초기
main스레드가 사용 가능한 스와프 슬롯을 나타내는 단일의 전역 비트맵을 생성하고 관리하도록 함으로써 이를 달성했습니다. - 이 비트맵은 이후의 모든 자식 프로세스에 의해 공유되고 접근됩니다.
is_immortal플래그:spt_entry구조체에is_immortal플래그가 중요하게 추가되었습니다.- 이 플래그는 중요한 페이지가 스와핑되는 것을 방지합니다.
- 초기 스택 페이지는 테스트 파일에서 메시지가 올바르게 출력되도록 메모리에 남아 있어야 하기 때문에 이는 필수적입니다.
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
thread.hstruct threadstruct thread는 이제 전역 스와프 공간 (global swap space)을 나타내는 부울 배열 (boolean array)에 대한 포인터인swap_slots을 포함합니다.- 이 배열의 크기는
SWAP_SIZE에 의해 정의됩니다.
- 이 배열의 크기는
- 또한, 희생 페이지를 효율적으로 찾기 위해 사용되는 클럭 알고리즘의 “핸드” (hand)를 추적하는 정수인
current_clock_index를 포함합니다.- 이 인덱스는
init_thread()에서0으로 초기화됩니다.
- 이 인덱스는
Click to see the refined code
#define SWAP_SIZE 1024 struct thread { // other code void *initial_code_segment; /* address of code segment */ bool *swap_slots; /* swap slot */ int current_clock_index; /* current index of page for clock algorithm*/ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
thread.cglobal_swap_slots- 부울 배열인
global_swap_slots이 메인 스레드 (main thread)와 그 자식 스레드 (child threads)가 전역적으로 접근할 수 있도록 도입되었으며, 할당된 스와프 섹터 (swap sectors)에 대한 중앙 기록 역할을 합니다.
Click to see the refined code
/* Global Swap Slots */ bool global_swap_slots[SWAP_SIZE];- 부울 배열인
thread_init()thread_init()는main스레드의initial_thread->swap_slots에global_swap_slots를 할당합니다.Click to see the refined code
void thread_init (void) { // other codes initial_thread->tid = allocate_tid (); /* Set up swap slot */ initial_thread->swap_slots = global_swap_slots; }init_thread()init_thread()는 모든 자식 프로세스 또한 자신의swap_slots이 동일한global_swap_slots배열을 가리키도록 보장하여, 모든 스레드가 동일한 전역 스와프 공간을 공유하고 관리하도록 합니다.- 또한, 각 새 스레드의
current_clock_index를0으로 초기화합니다.
Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_running_file = NULL; #endif /* child shares the swap slot */ t->swap_slots = global_swap_slots; t->current_clock_index = 0; old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
page.hstruct spt_entrystruct spt_entry는 두 개의 새로운 필드로 확장되었습니다:slot_index:- 페이지 내용이 저장되어 있거나 저장될 스와프 공간 (swap space) 내의 인덱스를 저장합니다.
- 페이지가 현재 스와프에 있지 않음을 나타내기 위해
-1로 초기화됩니다.
is_immortal:- 중요한 페이지가 축출되는 것을 보호하기 위한 부울 플래그 (boolean flag)입니다.
- 다음 중 하나에 해당하는 경우
is_immortal은true여야 합니다:- 초기 스택 페이지 (initial stack page),
- 데이터 세그먼트 (data segment)의 첫 두 페이지 중 하나,
- 코드 세그먼트 (code segment)에 속하는 페이지,
- 또는 파일 지원 페이지 (file-backed pages)의 첫 페이지.
- 현재,
load_segment(),page_fault(), 그리고setup_stack()이 이러한 필드를 초기화하는 역할을 담당합니다.
Click to see the refined code
struct spt_entry { // other codes bool writable; int slot_index; // needed to check whether it's related to swap space or not bool is_immortal; // needed for page swap struct list_elem sptelem; // List element for page table };
page.c- 스와프 공간 관련 함수 (Functions for Swap Space)
- 스와프 공간 사용을 위한 네 가지 사용자 정의 유틸리티 함수가 도입되었습니다.
block_read()및block_write()는PGSIZE($4096 \text{ bytes}$)가 아닌BLOCK_SECTOR_SIZE($512 \text{ bytes}$)를 기반으로 작동한다는 점에 유의해야 합니다.- 그 결과, 단일 페이지를 처리하려면 8번의 블록 작업 (
PGSIZE / BLOCK_SECTOR_SIZE = 8)이 필요합니다.
- 그 결과, 단일 페이지를 처리하려면 8번의 블록 작업 (
Click to see the refined code
/* Returns the available slot index of swap_slots table */ int allocate_swap_index(void) { struct thread* current_thread = thread_current(); // The trick here is that swap_slots is incremented singly, // but when the current_slot is returned, it should be multiplied by // PGSIZE / BLOCK_SECTOR_SIZE, because one page holds 8 sectors. for (int current_slot = 0; current_slot < SWAP_SIZE; ++current_slot) { if (current_thread->swap_slots[current_slot] == false) { current_thread->swap_slots[current_slot] = true; return current_slot; } } return -1; // No free slot available } /* Frees the given slot_index of swap_slots table */ void free_swap_index(int slot_index) { if (slot_index >= 0 && slot_index < SWAP_SIZE) thread_current()->swap_slots[slot_index] = false; } /* Flushes the chosen page to swap space */ void write_to_swap_space(struct spt_entry *target_entry) { target_entry->slot_index = allocate_swap_index(); int actual_sector_start_index = target_entry->slot_index * (PGSIZE/BLOCK_SECTOR_SIZE); if(target_entry->slot_index != -1) { const char *target_page = pagedir_get_page(thread_current()->pagedir, target_entry->vaddr); int current_sector_count = 0, end_count = PGSIZE/BLOCK_SECTOR_SIZE; while(current_sector_count < end_count) { // The start index for the slot should be adjusted by // PGSIZE / BLOCK_SECTOR_SIZE. block_write(block_get_role(BLOCK_SWAP), actual_sector_start_index + current_sector_count, target_page); ++current_sector_count; target_page += BLOCK_SECTOR_SIZE; } } } /* Reads a page from swap space */ void read_from_swap_space(void *kpage, int slot_index) { const char *target_page = kpage; int actual_sector_start_index = slot_index * (PGSIZE/BLOCK_SECTOR_SIZE); int current_sector_count = 0, end_count = PGSIZE/BLOCK_SECTOR_SIZE; while(current_sector_count < end_count) { // The start index for the slot should be adjusted by // PGSIZE / BLOCK_SECTOR_SIZE. block_read(block_get_role(BLOCK_SWAP), actual_sector_start_index + current_sector_count, target_page); ++current_sector_count; target_page += BLOCK_SECTOR_SIZE; } free_swap_index(slot_index); } pick_victim_page()- 이 함수는 클럭 알고리즘 (Clock Algorithm)을 구현하여 축출할 페이지를 선택합니다.
- 현재 스레드의
supplemental_page_table을current_clock_index부터 시작하여 순회합니다.- 축출 불가능하지 않고 (non-immortal), 현재 로드된 각 페이지에 대해, 페이지의 “접근됨” 비트 (accessed bit)를 확인합니다.
- 비트가 설정되어 있으면 (
1인 경우),- 비트를 지우고 (
0으로 만들고) 알고리즘은 계속 진행합니다.
- 비트를 지우고 (
- 비트가 지워져 있으면 (
0인 경우),- 해당 페이지가 희생 페이지로 선택됩니다.
current_clock_index는 리스트의 다음 페이지부터 스캔을 계속하도록 업데이트됩니다.
- 이는 공정하고 효율적인 선택 프로세스를 보장하며, 최근에 접근되지 않은 페이지를 선호합니다.
Click to see the refined code
/* Selects a victim page to evict */ struct spt_entry* pick_victim_page() { struct thread *current_thread = thread_current(); struct spt_entry *target_spt_entry = NULL; bool is_full_cycle = false; struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table); struct list_elem *end_element = list_end(¤t_thread->supplemental_page_table); if (current_element == end_element) return NULL; // No pages to swap int current_index = 0; while (current_index < current_thread->current_clock_index && current_element != end_element) { current_element = list_next(current_element); ++current_index; } if (current_element == end_element) { current_thread->current_clock_index = 0; current_element = list_begin(¤t_thread->supplemental_page_table); } while (true) { if (current_element == end_element) { if (is_full_cycle) { // Completed a full cycle; force selection of first loaded page current_element = list_begin(¤t_thread->supplemental_page_table); current_index = 0; while (current_element != end_element) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if (target_spt_entry->is_immortal == false && pagedir_get_page(current_thread->pagedir, target_spt_entry->vaddr) != NULL) { current_thread->current_clock_index = current_index + 1; return target_spt_entry; } ++current_index; current_element = list_next(current_element); } return NULL; // No loaded pages found } current_thread->current_clock_index = 0; current_element = list_begin(¤t_thread->supplemental_page_table); is_full_cycle = true; continue; } // Process the page at current_clock_index target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if (target_spt_entry->is_immortal == false && pagedir_get_page(current_thread->pagedir, target_spt_entry->vaddr) != NULL) { if (pagedir_is_accessed(current_thread->pagedir, target_spt_entry->vaddr) == false) { ++current_thread->current_clock_index; return target_spt_entry; } pagedir_set_accessed(current_thread->pagedir, target_spt_entry->vaddr, false); } ++current_thread->current_clock_index; current_element = list_next(current_element); } }evict_page()- 이 함수는 축출 프로세스를 조정 (orchestrates)합니다.
- 이 함수는 먼저 페이지의 데이터가 디스크에 다시 기록되어야 하는지 확인합니다.
- 페이지가
SPT_ANON인 경우,- 해당 내용은
write_to_swap_space()를 통해 스와프 공간에 기록됩니다.
- 해당 내용은
- 파일 지원 페이지 (
SPT_FILE)이고 수정된 경우 (is dirty == true),- 해당 내용은
file_write_at()을 사용하여 원래 파일에 다시 기록됩니다.
- 해당 내용은
- 페이지가
- 그 후, 선택된 물리 페이지 프레임은
palloc_free_page()를 사용하여 해제되고, 해당 매핑은 페이지 디렉토리에서 제거됩니다.
Click to see the refined code
/* Flushes the chosen page to swap space or the original physical address based on its type */ void evict_page(struct spt_entry* target_entry) { if(target_entry == NULL) return; struct thread *current_thread = thread_current(); // swap out DATA segment to SWAP SPACE as well if(target_entry->type == SPT_BIN) target_entry->type = SPT_ANON; if(target_entry->type == SPT_ANON) write_to_swap_space(target_entry); else { // this section is for mmap if(pagedir_is_dirty(current_thread->pagedir, target_entry->vaddr)) { file_write_at(target_entry->file, pagedir_get_page(current_thread->pagedir, target_entry->vaddr), PGSIZE, target_entry->offset); pagedir_set_dirty(current_thread->pagedir, target_entry->vaddr, false); } } palloc_free_page(pagedir_get_page(current_thread->pagedir, target_entry->vaddr)); pagedir_clear_page(current_thread->pagedir, target_entry->vaddr); }handle_page_fault()- 이 함수는 이제 페이지 스와핑을 지원하도록 완전히 구현되었습니다.
palloc_get_page()가 실패하면 (메모리 고갈을 나타냄), 할당을 재시도하기 전에 메모리를 확보하기 위해 세 개의 희생 페이지에 대해evict_page()를 호출합니다.- 물리 페이지가 성공적으로 할당되면 (초기 또는 축출 후),
handle_page_fault()는 페이지 내용을 어디에서 로드할지 결정합니다:target_spt_entry->slot_index가 해당 페이지가 스와프 공간에 있음을 나타내는 경우,read_from_swap_space()가 호출됩니다.
- 그렇지 않은 경우,
file_read_at()을 통해 원래 파일에서 데이터가 읽힙니다.
Click to see the refined code
/* Handles the page fault */ bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); if (kpage == NULL) { // swap out 3 pages whenever memory becomes full for(int current_count = 0; current_count < 3; ++current_count) evict_page(pick_victim_page()); kpage = palloc_get_page (PAL_USER | PAL_ZERO); if(kpage == NULL) { // failed to evict if(is_lock_already_owned == false) lock_release(&filesys_lock); return false; } } // load the data from disk if(target_spt_entry->type == SPT_ANON) { // if the page is stored in swap space, read from there if(target_spt_entry->slot_index != -1) read_from_swap_space(kpage, target_spt_entry->slot_index); } else { // otherwise read from the disk if(file_read_at(target_spt_entry->file, kpage, target_spt_entry->read_bytes, target_spt_entry->offset) != target_spt_entry->read_bytes) { palloc_free_page (kpage); if(is_lock_already_owned == false) lock_release(&filesys_lock); return false; } } if(is_lock_already_owned == false) lock_release(&filesys_lock); // update page table if (!install_page (target_spt_entry->vaddr, kpage, target_spt_entry->writable)) { palloc_free_page (kpage); return false; } return true; }
- 스와프 공간 관련 함수 (Functions for Swap Space)
process.cload_segment()load_segment()는 이제 새로 생성된 엔트리에 대해slot_index를-1로 설정합니다.- 더욱이, 특정 중요 페이지 (코드 세그먼트 페이지 및 첫 두 데이터 세그먼트 페이지)를 조기 축출을 방지하기 위해
is_immortal = true로 표시합니다.
Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { // other codes bool is_code_segment = current_thread->initial_code_segment == NULL; bool is_first_or_second_data_segment = true; bool temp_flag = true; while (read_bytes > 0 || zero_bytes > 0) { // other codes new_entry->vaddr = upage; if (current_thread->initial_code_segment == NULL) current_thread->initial_code_segment = upage; new_entry->zero_bytes = page_zero_bytes; new_entry->file = file; new_entry->read_bytes = page_read_bytes; new_entry->offset = ofs; new_entry->writable = writable; new_entry->slot_index = -1; if(is_code_segment || is_first_or_second_data_segment) { new_entry->is_immortal = true; if(temp_flag) temp_flag = false; else is_first_or_second_data_segment = false; } else new_entry->is_immortal = false; // other codse } return true; }setup_stack()setup_stack()는 초기 스택 페이지의slot_index또한-1로 설정합니다.- 나아가, 스택의 첫 페이지이므로
is_immortal을true로 초기화합니다.
Click to see the refined code
static bool setup_stack (void **esp) { // other codes new_entry->type = SPT_ANON; new_entry->is_stack = true; new_entry->vaddr = current_thread->current_stack_top; new_entry->file = NULL; new_entry->writable = true; new_entry->slot_index = -1; new_entry->is_immortal = true; list_push_back(¤t_thread->supplemental_page_table, &new_entry->sptelem); return success; }
결론
- 이러한 개선 사항들로 인해, PintOS는 이제 요구 페이징 (demand paging)과 페이지 스와핑 (page swapping)에 대한 견고한 지원을 제공합니다.
- 시스템은 요구에 따라 페이지를 로드함으로써 페이지 폴트를 효과적으로 처리할 수 있으며, 물리 메모리가 가득 찼을 때 덜 사용되는 페이지를 전용 스와프 공간으로 축출함으로써 메모리 고갈을 방지할 수 있습니다.
- 이는 사용 가능한 물리적 RAM보다 더 많은 프로세스를 동시에 실행하고 더 큰 애플리케이션을 처리하는 시스템의 능력을 획기적으로 향상시킵니다.
- 하지만, 현재 구현은
mmap()과 그와 관련된 메모리 매핑 기능을 완전히 처리하지는 못합니다. 특히 더티 페이지 (dirty page) 관리 및 직접적인 파일 지원 페이지 축출 로직 측면에서 그러하며, 이는 예비 조항만 포함되어 있습니다.- 메모리 매핑된 파일 (memory-mapped files)을 완전히 지원하고 모든 고급 메모리 작업을 원활하게 처리하여 포괄적인 가상 메모리 서브시스템을 완성하기 위해서는 추가적인 개선이 필요합니다.
Part 4: 메모리 매핑 기능 (Memory Mapping Features)
목표
- 마지막 부분의 목표는 PintOS에
mmap()및munmap()시스템 호출을 구현하는 것입니다. - 이 기능은 프로세스가 파일을 자신의 가상 주소 공간에 직접 매핑할 수 있도록 하여, 파일 내용이 마치 메모리에 있는 것처럼 접근되게 합니다. 이로써 I/O 효율성을 높이고 프로세스 간 통신 (inter-process communication)을 용이하게 합니다.
기존 문제
- 이전 PintOS는
mmap()및munmap()을 지원하지 않았습니다.
해결책
- 따라서, 저는 새로운 데이터 구조와 강력한 겹침 검사를 포함하여
mmap()및munmap()을 구현했습니다:mmap_entry구조체:- 새로운 데이터 구조인
struct mmap_entry가 생성되었습니다. - 이 구조체는 단일 메모리 매핑된 파일과 관련된 모든 필수 메타데이터를 위한 컨테이너 역할을 합니다.
- 매핑을 위한 고유한
map_id, 매핑이 차지하는 총number_of_pages,mapped_file객체에 대한 포인터, 그리고 이 메모리 매핑 영역을 구성하는 모든 개별spt_entry객체를 관리하기 위한 리스트 (loaded_spt_entries)를 기록합니다.
- 새로운 데이터 구조인
- 스레드별
mmap_table:- 각 스레드의
struct thread는 이제 해당 프로세스에 대해 현재 활성화된 모든mmap_entry객체를 저장하는 리스트인mmap_table을 포함하도록 확장되었습니다. - 이는 모든 메모리 매핑된 파일에 대한 명확한 프로세스별 기록을 제공합니다.
- 각 스레드의
- 겹침 감지 (Overlap Detection):
- 메모리 매핑 충돌을 방지하기 위해 핵심 함수인
is_mmap_overlapped()가 개발되었습니다. - 이 함수는 새로운 메모리 매핑 요청이 기존 메모리 매핑, 프로그램의 코드 및 데이터 세그먼트, 또는 스택 영역과 겹치지 않도록 보장합니다.
- 데이터 세그먼트 검사를 용이하게 하기 위해, 새로운
final_data_segment멤버가struct thread에 추가되었습니다.
- 메모리 매핑 충돌을 방지하기 위해 핵심 함수인
mmap()시스템 호출 구현:mmap()시스템 호출은 이제 몇 가지 중요한 단계를 수행합니다:
- 파일 디스크립터 및 요청된 가상 주소를 포함하여 입력 인수를 검증합니다.
file_reopen()을 사용하여 매핑을 위한 새로운 독립적인 파일 객체를 생성합니다.- 이는 동일한 기본 파일에 대한 다른 파일 작업과의 간섭을 방지하는 데 필수적입니다.
is_mmap_overlapped()를 호출하여 요청된 매핑 영역이 비어 있는지 확인합니다.- 새로운
mmap_entry를 할당하고, 매핑 세부 정보로 채우고, 고유한map_id를 생성합니다. - 매핑된 파일 내의 각 페이지에 대해,
SPT_FILE유형의spt_entry를 생성하고, 이를mmap_entry의 내부 리스트 (loaded_spt_entries)와 스레드의 전체supplemental_page_table모두에 추가합니다.- 매핑의 첫 페이지에 대한
is_immortal플래그는 초기 존재를 보장하기 위해true로 설정됩니다.
- 매핑의 첫 페이지에 대한
- 마지막으로,
mmap_entry는 스레드의mmap_table에 추가되고, 고유한map_id가 사용자 프로세스에 반환됩니다.
munmap()시스템 호출 구현:munmap()시스템 호출은 매핑 해제 프로세스를 처리합니다:
- 제공된
map_id에 해당하는mmap_entry를 찾습니다. - 해당
mmap_entry와 연결된 모든spt_entry객체를 순회합니다.- 현재 물리 메모리에 있고 수정된 (dirty) 각 페이지에 대해, 그 내용이 원래 파일에 다시 기록됩니다.
- 그런 다음, 물리 페이지 프레임은 해제되고, 해당 매핑은 페이지 디렉토리에서 제거됩니다.
- 마지막으로,
spt_entry객체,mmap_entry자체, 그리고 관련 파일 객체가 적절하게 닫히고 할당 해제됩니다.
process_exit()및page_fault()와의 통합:process_exit()는 프로세스가 종료될 때 스레드의mmap_table에 남아 있는 모든mmap_entry객체에 대해 자동으로munmap()을 호출하도록 업데이트되었습니다.
- 이는 적절한 정리 및 수정된 데이터의 지속성을 보장합니다.
-
page_fault()는 일반적인 보조 페이지 테이블 외에mmap_table도 참조하도록 확장되었습니다. - 메모리 매핑된 영역 내의 가상 주소에 대해 페이지 폴트가 발생하면,
page_fault()는 이제handle_page_fault()에게 적절한 파일 지원 페이지를 로드하도록 지시합니다.
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
page.hstruct mmap_entry- 메모리 매핑 정보를 저장하기 위한 새로운 구조체인
struct mmap_entry가 정의되었습니다. - 이 구조체는 다음을 포함합니다:
map_id: 메모리 매핑을 위한 고유 식별자입니다.number_of_pages: 이 매핑과 관련된 총 메모리 페이지 수입니다.mapped_file: 메모리 매핑되는file객체에 대한 포인터입니다.loaded_spt_entries: 이 메모리 매핑 영역을 구성하는 페이지에 해당하는spt_entry객체들의 리스트입니다.
Click to see the refined code
/* mmap_entry for mmap_table in each thread */ struct mmap_entry { int map_id; int number_of_pages; struct file *mapped_file; struct list loaded_spt_entries; // List for loaded spt_entry struct list_elem mmelem; // List element for mapping table };- 메모리 매핑 정보를 저장하기 위한 새로운 구조체인
thread.hstruct threadstruct thread는 다음을 추가하여 강화되었습니다:mmap_table:mmap_entry객체를 관리하기 위해 설계된 리스트입니다.current_available_map_id: 새로운 메모리 매핑을 위한 고유한map_id를 생성하는 데 사용되는 식별자입니다.final_data_segment: 프로그램의 데이터 세그먼트의 종료 지점을 표시하는 포인터이며, 메모리 매핑 작업 중 겹침 검사 (overlap checks)를 수행하는 데 매우 중요합니다.
Click to see the refined code
struct thread { // other codes bool *swap_slots; /* swap slot */ int current_clock_index; /* current index of page for clock algorithm*/ struct list mmap_table; /* memory mapping table for mmap() */ int current_available_map_id; /* id for mmap_entry */ void *final_data_segment; /* address of data segment */ /* Owned by thread.c. */ unsigned magic; /* Detects stack overflow. */ };
thread.cinit_thread()init_thread()내에서,mmap_table및current_available_map_id가 새로 생성된 스레드에 대해 초기화되었습니다.
Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_clock_index = 0; list_init(&t->mmap_table); t->current_available_map_id = 0; old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }
process.cload_segment()- 이 함수는 이제 실행 파일의 데이터 세그먼트 (data segment)를 로드한 직후에 스레드에 대한
final_data_segment를 설정합니다.
Click to see the refined code
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { // other codes while (read_bytes > 0 || zero_bytes > 0) { // other codes ofs += PGSIZE; }/* Advance. */ if (is_code_segment == false) current_thread->final_data_segment = upage; return true; }- 이 함수는 이제 실행 파일의 데이터 세그먼트 (data segment)를 로드한 직후에 스레드에 대한
process_exit()- 이 함수는
mmap_table에 남아 있는 각 엔트리에 대해munmap()을 호출하도록 업데이트되었습니다. 이는 프로세스가 종료될 때 데이터 지속성 (data persistence)과 적절한 자원 할당 해제를 보장합니다.
Click to see the refined code
void process_exit (void) { // other codes /* deallocate supplemental page table */ for(struct list_elem *current_element = list_begin(&cur->supplemental_page_table), *end_element = list_end(&cur->supplemental_page_table), *next_element; current_element != end_element;) { struct spt_entry *target_entry = list_entry(current_element, struct spt_entry, sptelem); next_element = list_next(current_element); list_remove(current_element); free(target_entry); current_element = next_element; } /* deallocate mmap table */ for(struct list_elem *current_element = list_begin(&cur->mmap_table), *end_element = list_end(&cur->mmap_table), *next_element; current_element != end_element;) { struct mmap_entry *target_mmap = list_entry(current_element, struct mmap_entry, mmelem); current_element = list_next(current_element); munmap(target_mmap->map_id); } // other codes }- 이 함수는
syscall.cmmap()- 이 새로운 함수는
file_reopen()을 호출하여mmap()으로부터의file객체가 기존의 어떤 객체와도 독립적임을 보장합니다. - 또한,
is_mmap_overlapped()를 활용하여 주소 공간 충돌을 확인합니다. - 첫 페이지에 대해서는
is_immortal을true로 설정했습니다.
Click to see the refined code
int mmap(int fd, void *addr) { struct thread *current_thread = thread_current(); lock_acquire(&filesys_lock); if(current_thread->fd_table[fd] == NULL || addr == NULL || is_user_vaddr(addr) == false || (uintptr_t)addr % PGSIZE != 0) { lock_release(&filesys_lock); return -1; } lock_release(&filesys_lock); struct mmap_entry *new_mmap_entry = malloc(sizeof(struct mmap_entry)); if(new_mmap_entry == NULL) exit(-1); list_init(&new_mmap_entry->loaded_spt_entries); new_mmap_entry->map_id = current_thread->current_available_map_id; ++current_thread->current_available_map_id; lock_acquire(&filesys_lock); // file_reopen() is needed to create a separate file object new_mmap_entry->mapped_file = file_reopen(current_thread->fd_table[fd]); int read_bytes = file_length(new_mmap_entry->mapped_file); new_mmap_entry->number_of_pages = (read_bytes + PGSIZE - 1) / PGSIZE; if(is_mmap_overlapped(addr, new_mmap_entry->number_of_pages) == true) { file_close(new_mmap_entry->mapped_file); --current_thread->current_available_map_id; free(new_mmap_entry); lock_release(&filesys_lock); return -1; } lock_release(&filesys_lock); int offset = 0; bool is_first_page = true; while (read_bytes > 0) { size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; struct spt_entry *new_spt_entry = malloc(sizeof(struct spt_entry)); if(new_spt_entry == NULL) return false; new_spt_entry->type = SPT_FILE; new_spt_entry->is_stack = false; new_spt_entry->vaddr = addr; new_spt_entry->zero_bytes = page_zero_bytes; new_spt_entry->file = new_mmap_entry->mapped_file; new_spt_entry->read_bytes = page_read_bytes; new_spt_entry->offset = offset; new_spt_entry->writable = true; new_spt_entry->slot_index = -1; if(is_first_page) { new_spt_entry->is_immortal = true; is_first_page = false; } else new_spt_entry->is_immortal = false; list_push_back(&new_mmap_entry->loaded_spt_entries, &new_spt_entry->sptelem); // Advance. read_bytes -= page_read_bytes; addr += PGSIZE; offset += PGSIZE; } list_push_back(¤t_thread->mmap_table, &new_mmap_entry->mmelem); return new_mmap_entry->map_id; }- 이 새로운 함수는
is_mmap_overlapped()- 이 새로운 함수는 모든
mmap_entry객체에 대해 겹침을 확인합니다. - 또한, 주어진 메모리 범위가 데이터 세그먼트의 끝 이전 영역 또는 스택 세그먼트의 최상단 이후 영역과 충돌하지 않는지 검증합니다.
Click to see the refined code
bool is_mmap_overlapped(void *vaddr_start, int number_of_pages) { struct thread *current_thread = thread_current(); void *vaddr_end = vaddr_start + number_of_pages * PGSIZE; void *mmap_start = NULL, *mmap_end = NULL; for(struct list_elem *current_element_mmap = list_begin(¤t_thread->mmap_table), *end_element_mmap = list_end(¤t_thread->mmap_table); current_element_mmap != end_element_mmap; current_element_mmap = list_next(current_element_mmap)) { struct mmap_entry *current_mmap_entry = list_entry(current_element_mmap, struct mmap_entry, mmelem); for(struct list_elem *current_element_spt = list_begin(¤t_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(¤t_mmap_entry->loaded_spt_entries); current_element_spt != end_element_spt; current_element_spt = list_next(current_element_spt)) { struct spt_entry *current_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); mmap_start = current_spt_entry->vaddr; mmap_end = mmap_start + PGSIZE; if (!(vaddr_end <= mmap_start || vaddr_start >= mmap_end)) return true; } } // check data segment if (vaddr_start < current_thread->final_data_segment) return true; // check stack if (vaddr_end > thread_current()->current_stack_top) return true; return false; }- 이 새로운 함수는 모든
munmap()- 이 새로운 함수는 현재 스레드의
mmap_table에서 대상mmap_entry를 제거합니다. - 그런 다음, 해당하는
file객체를 닫고 (closes), 대상mmap_entry와 관련된 모든 페이지 및 이와 연관된spt_entry객체를 해제합니다 (frees).
Click to see the refined code
void munmap(int map_id) { struct thread *current_thread = thread_current(); struct mmap_entry *target_mmap_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->mmap_table), *end_element = list_end(¤t_thread->mmap_table); current_element != end_element; current_element = list_next(current_element)) { target_mmap_entry = list_entry(current_element, struct mmap_entry, mmelem); if(target_mmap_entry->map_id == map_id) { list_remove(current_element); break; } } if(target_mmap_entry == NULL) exit(-1); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); for(struct list_elem *current_element_spt = list_begin(&target_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(&target_mmap_entry->loaded_spt_entries), *next_element_spt; current_element_spt != end_element_spt;) { struct spt_entry *current_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); next_element_spt = list_next(current_element_spt); list_remove(current_element_spt); if(pagedir_is_dirty(current_thread->pagedir, current_spt_entry->vaddr)) { file_write_at(current_spt_entry->file, pagedir_get_page(current_thread->pagedir, current_spt_entry->vaddr), current_spt_entry->read_bytes, current_spt_entry->offset); pagedir_set_dirty(current_thread->pagedir, current_spt_entry->vaddr, false); } palloc_free_page(pagedir_get_page(current_thread->pagedir, current_spt_entry->vaddr)); pagedir_clear_page(current_thread->pagedir, current_spt_entry->vaddr); free(current_spt_entry); current_element_spt = next_element_spt; } file_close(target_mmap_entry->mapped_file); if(is_lock_already_owned == false) lock_release(&filesys_lock); free(target_mmap_entry); }- 이 새로운 함수는 현재 스레드의
syscall_handler()- 이 함수는 새로 추가된
mmap()및munmap()함수로 호출을 적절하게 디스패치 (dispatch)하도록 수정되었습니다.
Click to see the refined code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { // other codes case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; } }- 이 함수는 새로 추가된
exception.cpage_fault()- 페이지 폴트 핸들러 (page fault handler)가 완전히 수정되었습니다.
- 따라서, 이제 페이지 폴트를 해결할 때
mmap_table엔트리를 확인하여, 파일 지원 페이지 (file-backed pages)를 요구에 따라 올바르게 로드할 수 있게 되었습니다.
- 따라서, 이제 페이지 폴트를 해결할 때
Click to see the refined code
static void page_fault (struct intr_frame *f) { // other codes // handle page demanding struct spt_entry *target_spt_entry = NULL; for(struct list_elem *current_element = list_begin(¤t_thread->supplemental_page_table), *end_element = list_end(¤t_thread->supplemental_page_table); current_element != end_element; current_element = list_next(current_element)) { target_spt_entry = list_entry(current_element, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } // handle memory-mapped file for(struct list_elem *current_element_mmap = list_begin(¤t_thread->mmap_table), *end_element_mmap = list_end(¤t_thread->mmap_table); current_element_mmap != end_element_mmap; current_element_mmap = list_next(current_element_mmap)) { struct mmap_entry *current_mmap_entry = list_entry(current_element_mmap, struct mmap_entry, mmelem); for(struct list_elem *current_element_spt = list_begin(¤t_mmap_entry->loaded_spt_entries), *end_element_spt = list_end(¤t_mmap_entry->loaded_spt_entries); current_element_spt != end_element_spt; current_element_spt = list_next(current_element_spt)) { target_spt_entry = list_entry(current_element_spt, struct spt_entry, sptelem); if(target_spt_entry->vaddr <= fault_addr && (target_spt_entry->vaddr + PGSIZE) > fault_addr) { if(handle_page_fault(target_spt_entry)) return; else exit(-1); } } } // other codes }- 페이지 폴트 핸들러 (page fault handler)가 완전히 수정되었습니다.
결론
- PintOS는 이제 페이징 (paging), 페이지 스와핑 (page swapping), 그리고 메모리 매핑 (memory mapping)을 포함하는 완벽한 메모리 관리 기능을 갖추게 되었습니다.
- 시스템은 파일 지원 페이지 (file-backed pages), 스택 확장 (stack growth)을 처리하며, 익명 페이지 (anonymous pages)와 메모리 매핑된 페이지 (memory-mapped pages) 모두에 대한 적절한 관리를 보장합니다.
향상된 점수
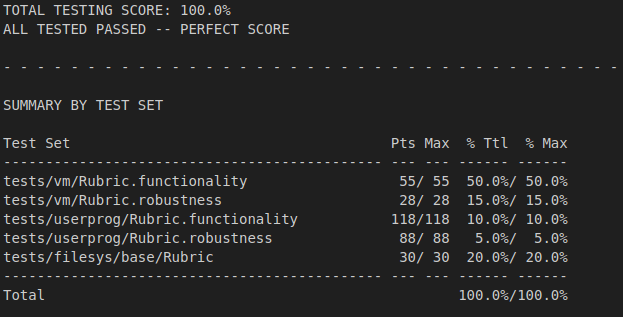
최종 의견
- PintOS의 메모리 관리는 통합된 요구 페이징 (demand paging), 견고한 페이지 스와핑 (page swapping), 그리고 완벽한 메모리 매핑 (memory mapping) 지원을 통해 획기적으로 발전했습니다.
- 이는 요구에 따라 페이지를 할당하여 메모리 활용도를 최적화하고, 지능적인 축출 (eviction)을 통해 메모리 압력을 관리하며, 데이터 지속성을 보장합니다.
- 결과적으로 복잡한 애플리케이션을 위한 더욱 탄력적이며 고성능의 OS가 되었습니다.
Leave a comment