Project 4: File Systems
파일 시스템 (File Systems)
- 네 번째 프로젝트는 궁극적인 PintOS를 완성하기 위한 마지막 부분을 채웁니다.
- 이 최종 단계에는 다음이 포함됩니다:
- 버퍼 캐시 (buffer cache) 구현.
- 파일 확장 가능 (extensible)하게 만들기.
- 서브 디렉토리 (subdirectories) 도입.
-
아래에서는 각 구성 요소에 대한 목표, 도전 과제, 해결책, 구현 내용을 간략하게 설명했습니다.
Part 1: 버퍼 캐시 (Buffer Cache)
목표
- 주요 목표는 디스크 I/O 작업을 최적화하기 위해 버퍼 캐시를 구현하는 것입니다.
- 이는 디스크 읽기 및 쓰기를 메모리 내의 버퍼 캐시를 통해 라우팅하여, 느린 디스크에 대한 직접 접근을 줄임으로써 전반적인 시스템 성능을 획기적으로 향상시키는 것을 포함합니다.
기존 문제
- 현재 PintOS에는 버퍼 캐시가 없습니다.
- 결과적으로, 원래의
block_read()및block_write()함수는 호출될 때마다 디스크에 직접 접근하여 비효율적인 I/O 작업을 초래했습니다.
Click to see the original code
void block_read (struct block *block, block_sector_t sector, void *buffer) { check_sector (block, sector); block->ops->read (block->aux, sector, buffer); block->read_cnt++; } void block_write (struct block *block, block_sector_t sector, const void *buffer) { check_sector (block, sector); ASSERT (block->type != BLOCK_FOREIGN); block->ops->write (block->aux, sector, buffer); block->write_cnt++; } - 결과적으로, 원래의
원래 점수
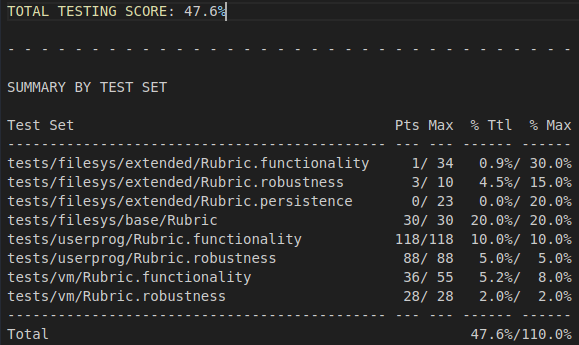
해결책
- 버퍼 캐시 개념을 구현하기 위해 저는 다음을 도입했습니다:
block_read_buffer_cache()및block_write_buffer_cache()- 이들은 파일 시스템의 상위 레벨에서 오는 모든 디스크 읽기 및 쓰기 요청을 처리하는 새로운 주 함수입니다.
- 이들은 버퍼 캐시로의 인터페이스 역할을 합니다.
block_read_buffer_cache()가 호출되면,- 요청된 블록이 먼저 캐시에 있는지 확인합니다.
- 있다면 (캐시 적중), 메모리에서 데이터를 직접 제공합니다.
- 블록이 캐시에 없다면 (캐시 미스), 데이터를 반환하기 전에 물리적 디스크에서 캐시 엔트리로 블록을 로드합니다.
- 요청된 블록이 먼저 캐시에 있는지 확인합니다.
block_write_buffer_cache()가 호출되면,- 버퍼 캐시의 해당 블록에 데이터를 기록합니다.
- 블록이 이미 캐시되지 않은 경우 (캐시 미스), 디스크에서 캐시로 블록을 먼저 로드한 다음 쓰기를 수행합니다.
- 캐시 엔트리는 디스크와 내용이 다르다는 것을 나타내기 위해 “더티“로 표시됩니다.
- 버퍼 캐시의 해당 블록에 데이터를 기록합니다.
- 저는 다음 경우에 파일 시스템이 버퍼 캐시를 플러시하도록 만들었습니다:
- 축출 기반 플러시 (Eviction-based Flush)
- 버퍼 캐시가 가득 차고 새 블록을 로드해야 하는 경우,
evict_buffer_cache_entry()함수가 호출됩니다. - 이 함수는 클럭 알고리즘을 사용하여 희생 블록을 선택합니다.
- 선택된 희생 블록이 더티 상태인 경우, 캐시 엔트리가 새 블록을 위해 용도가 변경되기 전에 해당 내용이 디스크로 플러시 (다시 기록)됩니다.
- 버퍼 캐시가 가득 차고 새 블록을 로드해야 하는 경우,
- 주기적 플러시 (Periodic Flush)
filesys_init()중에 시작된 전용 커널 스레드가 백그라운드에서 실행됩니다.- 이 스레드는 주기적으로 (5초마다) 깨어나
cached_mapping_table전체를 스캔하여 더티 블록이 있는지 확인합니다.
- 이 스레드는 주기적으로 (5초마다) 깨어나
- 발견된 모든 더티 블록은 비동기적으로 디스크에 다시 기록되어, 변경 사항을 사전에 저장하고 축출 또는 종료 시 기록해야 하는 데이터의 양을 줄입니다.
- 시스템 종료 플러시 (System Shutdown Flush)
- 시스템 종료 시 (
filesys_done()), 버퍼 캐시에 남아 있는 모든 더티 블록은 디스크에 명시적으로 플러시되어, 시스템 전원이 꺼지기 전에 모든 영구 데이터가 기록되도록 보장합니다.
- 시스템 종료 시 (
- 축출 기반 플러시 (Eviction-based Flush)
- 이 해결책을 달성하기 위해:
- 각 개별 캐시 블록을 나타내기 위해
struct buffer_entry를 정의했습니다.- 이는 디바이스, 섹터, 메모리 주소, 그리고 중요한
is_dirty및is_accessed플래그를 담고 있습니다.
- 이는 디바이스, 섹터, 메모리 주소, 그리고 중요한
- 전역 배열인
cached_mapping_table은 주 버퍼 캐시 역할을 하며, 이러한buffer_entry구조체를 저장합니다.- 전역
buffer_cache_lock은cached_mapping_table에 접근하거나 수정할 때 상호 배제 (mutual exclusion) 및 스레드 안전성을 보장합니다. - 동시 접근 중 아이노드 (inode) 데이터를 보호하기 위해
struct inode자체에inode_lock을 추가하여 동기화를 확장했습니다.
- 전역
- 중요하게도, 기존의
inode_read_at()및inode_write_at()함수는 새로운block_read_buffer_cache()및block_write_buffer_cache()함수를 활용하도록 재구현되어, 모든 파일 I/O를 버퍼 캐시를 통해 효율적으로 재라우팅합니다. struct thread에parent_thread_pointer를 추가하여 스레드 관리가 미묘하게 조정되었는데, 이는 부모 페이지 디렉토리에 접근할 수 있도록 하여 시스템 호출 유효성 검사 (is_valid_address())를 돕습니다.- 마지막으로,
handle_page_fault()함수는 페이지 폴트 발생 시 보유하고 있을 수 있는buffer_cache_lock을 일시적으로 해제하도록 신중하게 수정되어, 폴트 핸들러 자체가 I/O를 수행해야 할 때 발생할 수 있는 잠재적인 교착 상태 (deadlocks)를 방지합니다.
- 각 개별 캐시 블록을 나타내기 위해
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
block.hstruct buffer_entry- 이 새로운 구조체는 버퍼 캐시 내의 각 캐시된 블록에 대한 엔트리 역할을 합니다.
Click to see the refined code
/* Entry for each block in a buffer cache */ struct buffer_entry { struct block *target_block_device; /* target block device */ block_sector_t sector_index; /* physical address of this block in the disk */ void *cached_block; /* pointer to the actual address in memory for the cached block */ bool is_dirty; /* flag to check whether this block is modified or not */ bool is_accessed; /* flag for choosing a victim for the eviction */ };cached_mapping_table- 이것은 전체 버퍼 캐시를 나타내는
buffer_entry구조체의 전역 배열입니다. - 이는
filesys_init()중에 초기화되며, 필요할 때마다 엔트리가 디스크로 플러시됩니다.- 예를 들어, 시스템 종료 (
filesys_done()) 시 또는 버퍼 캐시 내의 특정 블록이 축출될 때 플러시됩니다.
Click to see the refined code
/* Buffer Cache */ #define BUFFER_CACHE_MAX_COUNT 64 struct buffer_entry cached_mapping_table[BUFFER_CACHE_MAX_COUNT]; - 예를 들어, 시스템 종료 (
- 이것은 전체 버퍼 캐시를 나타내는
buffer_cache_lock- 이것은
cached_mapping_table을 보호하여 버퍼 캐시에 대한 스레드 안전한 접근을 보장하는 전역 잠금 메커니즘입니다. - 이 잠금 또한
filesys_init()내에서 초기화됩니다.Click to see the refined code
/* Buffer Cache */ struct lock buffer_cache_lock;
- 이것은
신규 함수 선언block_read_buffer_cache()와block_write_buffer_cache()를 선언합니다.- 이 함수들은 버퍼 캐시를 통해 디스크로부터 읽고 쓰는 새로운 인터페이스 함수입니다.
Click to see the refined code
void block_read_buffer_cache(struct block *block, block_sector_t sector, void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset); void block_write_buffer_cache(struct block *block, block_sector_t sector, const void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset);
신규 해더 파일- 버퍼 캐시의 기능을 지원하기 위해 세 개의 헤더 파일 (
synch.h,vaddr.h,palloc.h)이 포함되었습니다.
Click to see the refined code
#include "threads/synch.h" #include "threads/vaddr.h" #include "threads/palloc.h"- 버퍼 캐시의 기능을 지원하기 위해 세 개의 헤더 파일 (
filesys.h신규 해더 파일filesys.c의 수정된 코드를 위해block.h를 포함합니다.Click to see the refined code
#include "devices/block.h"
filesys.cflush_buffer_cache()- 이 함수는
filesys_init()중에 시작된 별도의 스레드에 의해 실행됩니다. - 그 목적은 버퍼 캐시를 주기적으로 순회하여, 수정된 (
is_dirty) 블록을 식별하고 디스크에 다시 기록하는 것입니다.- 이러한 비동기적 플러싱은 일반적인 I/O 작업을 차단하지 않고 데이터 일관성을 유지하는 데 도움이 됩니다.
- 주기적인 플러싱 메커니즘을 용이하게 하기 위해
timer.h헤더가 포함되었습니다.
Click to see the refined code
#include "devices/timer.h" // other codes /* Periodically checks whether there's a dirty block. If there is, flush it */ void * flush_buffer_cache(void *arg) { while (is_terminated == false) { timer_sleep(TIMER_FREQ * 5); // waiting for 5 seconds lock_acquire(&buffer_cache_lock); for (int current_block_index = 0; current_block_index < BUFFER_CACHE_MAX_COUNT; ++current_block_index) { if (cached_mapping_table[current_block_index].target_block_device != NULL && cached_mapping_table[current_block_index].is_dirty) { // Flush! block_write(cached_mapping_table[current_block_index].target_block_device, cached_mapping_table[current_block_index].sector_index, cached_mapping_table[current_block_index].cached_block); cached_mapping_table[current_block_index].is_dirty = false; } } lock_release(&buffer_cache_lock); } return NULL; }- 이 함수는
filesys_init()- 이 함수는 이제 버퍼 캐시를 초기화하는 로직을 포함합니다.
buffer_cache_lock을 설정하고 캐시 엔트리를 위한 메모리 페이지를 할당합니다.- 중요하게도,
flush_buffer_cache()를 주기적으로 호출하는 전용 스레드를 생성하고 시작합니다.
Click to see the refined code
void filesys_init (bool format) { // Initialize buffer cache lock_init(&buffer_cache_lock); char *buffer_cache_page = palloc_get_page(PAL_USER | PAL_ZERO); for( int current_entry_index = 0, end_page_count = PGSIZE/BLOCK_SECTOR_SIZE, current_page_count = 0 ; current_entry_index < BUFFER_CACHE_MAX_COUNT ; ++current_entry_index, ++current_page_count) { if(current_page_count == end_page_count) { current_page_count = 0; buffer_cache_page = palloc_get_page(PAL_USER | PAL_ZERO); } cached_mapping_table[current_entry_index].target_block_device = NULL; cached_mapping_table[current_entry_index].cached_block = buffer_cache_page; buffer_cache_page += BLOCK_SECTOR_SIZE; } fs_device = block_get_role (BLOCK_FILESYS); // other codes dir_add (root_dir, ".", ROOT_DIR_SECTOR); // Execute dedicated thread for flushing the buffer cache periodically thread_create("bc_flusher", PRI_DEFAULT, flush_buffer_cache, NULL); }- 이 함수는 이제 버퍼 캐시를 초기화하는 로직을 포함합니다.
filesys_done()- 파일 시스템이 종료될 때,
filesys_done()은 자원이 할당 해제되기 전에 버퍼 캐시의 모든 더티 블록이 디스크에 다시 기록되도록 확장되었습니다.
- 이는 시스템 종료 시 데이터 손실이 없음을 보장합니다.
Click to see the refined code
void filesys_done (void) { free_map_close (); /* buffer cache */ void *buffer_cache_page = cached_mapping_table[0].cached_block; for( int current_entry_index = 0, end_page_count = PGSIZE/BLOCK_SECTOR_SIZE, current_page_count = 0 ; current_entry_index < BUFFER_CACHE_MAX_COUNT ; ++current_entry_index, ++current_page_count) { if(current_page_count == end_page_count) { current_page_count = 0; palloc_free_page (buffer_cache_page); buffer_cache_page = cached_mapping_table[current_entry_index].cached_block; } // flush modified block if(cached_mapping_table[current_entry_index].is_dirty) block_write (cached_mapping_table[current_entry_index].target_block_device , cached_mapping_table[current_entry_index].sector_index , cached_mapping_table[current_entry_index].cached_block); } }- 파일 시스템이 종료될 때,
block.cblock_read_buffer_cache()- 이 새로운 함수는 읽기 요청을 관리합니다.
- 요청된 블록이 이미
cached_mapping_table에 존재하는지 (캐시 적중) 먼저 확인합니다.- 캐시 미스가 발생하면, 비어 있는 슬롯을 찾으려고 시도합니다.
- 캐시가 가득 찬 경우, 공간을 확보하기 위해
evict_buffer_cache_entry()를 호출합니다.
- 대상 캐시 엔트리를 결정한 후,
- 필요한 경우 디스크에서 캐시로 블록을 읽어오고, 데이터를 사용자 버퍼로 복사한 다음, 엔트리를 접근됨으로 표시합니다.
- 동기화는
buffer_cache_lock을 사용하여 처리됩니다.
- 요청된 블록이 이미
- 이 함수는 두 개의 오프셋과 청크 크기 매개변수를 사용하여 부분 블록 읽기를 수용합니다.
- 이는 바운스 버퍼 (bounce buffers)를 처리하는 데 매우 중요합니다.
Click to see the refined code
/* Reads from buffer cache */ void block_read_buffer_cache (struct block *block, block_sector_t sector, void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset) { lock_acquire(&buffer_cache_lock); int current_entry_index = 0, temp_available_index = -1; for(; current_entry_index < BUFFER_CACHE_MAX_COUNT; ++current_entry_index) { if(temp_available_index == -1 && cached_mapping_table[current_entry_index].target_block_device == NULL) temp_available_index = current_entry_index; if(cached_mapping_table[current_entry_index].target_block_device != NULL && cached_mapping_table[current_entry_index].sector_index == sector) { break; } } if(current_entry_index == BUFFER_CACHE_MAX_COUNT) { // cache miss! // find free block if(temp_available_index == -1) { // if buffer cache is full, evict just like paging current_entry_index = evict_buffer_cache_entry(); } else current_entry_index = temp_available_index; // read block from disk block_read(block, sector, cached_mapping_table[current_entry_index].cached_block); // update entry cached_mapping_table[current_entry_index].target_block_device = block; cached_mapping_table[current_entry_index].sector_index = sector; cached_mapping_table[current_entry_index].is_dirty = false; } // cache hit! memcpy(buffer + buffer_offset, cached_mapping_table[current_entry_index].cached_block + cache_offset, chunk_size); cached_mapping_table[current_entry_index].is_accessed = true; lock_release(&buffer_cache_lock); }- 이 새로운 함수는 읽기 요청을 관리합니다.
evict_buffer_cache_entry()- 이 함수는 버퍼 캐시가 가득 찼을 때 축출할 희생 엔트리를 선택하기 위해 클럭 알고리즘을 구현합니다.
- 캐시 엔트리를 순회하며, 최근에 접근되지 않은 (
is_accessed == false) 블록을 찾습니다. - 더티 블록이 축출을 위해 선택된 경우, 엔트리가 재사용되기 전에 그 내용이 디스크에 플러시됩니다.
- 캐시 엔트리를 순회하며, 최근에 접근되지 않은 (
Click to see the refined code
/* Evicts the least recently used block in buffer cache by using the clock algorithm Returns the index of it. */ int evict_buffer_cache_entry() { static int current_clock_index = 0; bool is_full_cycle = false; int target_entry_index = current_clock_index; while(true) { if(current_clock_index == BUFFER_CACHE_MAX_COUNT) { current_clock_index = 0; if(is_full_cycle) { // Completed a full cycle; force selection of first loaded block // flush it if it's modified if(cached_mapping_table[current_clock_index].is_dirty) { block_write(cached_mapping_table[current_clock_index].target_block_device, cached_mapping_table[current_clock_index].sector_index, cached_mapping_table[current_clock_index].cached_block); } target_entry_index = current_clock_index; break; } else is_full_cycle = true; } if(cached_mapping_table[current_clock_index].is_accessed == false) { // flush it if it's modified if(cached_mapping_table[current_clock_index].is_dirty) { block_write(cached_mapping_table[current_clock_index].target_block_device, cached_mapping_table[current_clock_index].sector_index, cached_mapping_table[current_clock_index].cached_block); } target_entry_index = current_clock_index; break; } else cached_mapping_table[current_clock_index].is_accessed = false; ++current_clock_index; } ++current_clock_index; if(current_clock_index == BUFFER_CACHE_MAX_COUNT) current_clock_index = 0; return target_entry_index; }- 이 함수는 버퍼 캐시가 가득 찼을 때 축출할 희생 엔트리를 선택하기 위해 클럭 알고리즘을 구현합니다.
block_write_buffer_cache()- 이 새로운 함수는 쓰기 요청을 처리합니다.
block_read_buffer_cache()와 유사하게, 먼저 캐시 적중을 확인합니다.- 미스가 발생하고 사용 가능한 슬롯이 없으면,
evict_buffer_cache_entry()를 호출하여 공간을 만듭니다. - 그런 다음, 함수는 제공된 데이터를 캐시된 블록에 기록하고, 엔트리를 더티로 표시하며 (수정되었음을 나타냄), 접근 플래그를 설정합니다.
- 미스가 발생하고 사용 가능한 슬롯이 없으면,
- 동기화는
buffer_cache_lock으로 유지됩니다.
- 이 함수 또한 두 개의 오프셋과 청크 크기 매개변수를 사용하여 부분 블록 쓰기를 지원합니다.
Click to see the refined code
/* Writes sector to buffer cache */ void block_write_buffer_cache(struct block *block, block_sector_t sector, const void *buffer, int32_t buffer_offset, int chunk_size, int cache_offset) { lock_acquire(&buffer_cache_lock); int current_entry_index = 0, temp_available_index = -1; for(; current_entry_index < BUFFER_CACHE_MAX_COUNT; ++current_entry_index) { if(temp_available_index == -1 && cached_mapping_table[current_entry_index].target_block_device == NULL) temp_available_index = current_entry_index; if(cached_mapping_table[current_entry_index].target_block_device != NULL && cached_mapping_table[current_entry_index].sector_index == sector) { break; } } if(current_entry_index == BUFFER_CACHE_MAX_COUNT) { // cache miss! // find free block if(temp_available_index == -1) { // if buffer cache is full, evict just like paging current_entry_index = evict_buffer_cache_entry(); } else current_entry_index = temp_available_index; // read from the disk block_read(block, sector, cached_mapping_table[current_entry_index].cached_block); // update entry cached_mapping_table[current_entry_index].target_block_device = block; cached_mapping_table[current_entry_index].sector_index = sector; } // update entry memcpy(cached_mapping_table[current_entry_index].cached_block + cache_offset, buffer + buffer_offset, chunk_size); cached_mapping_table[current_entry_index].is_dirty = true; cached_mapping_table[current_entry_index].is_accessed = true; lock_release(&buffer_cache_lock); }- 이 새로운 함수는 쓰기 요청을 처리합니다.
inode.cstruct inode- 개별 아이노드 데이터에 대한 스레드 안전한 접근을 보장하기 위해
struct inode에 새로운inode_lock이 추가되었습니다.- 이 잠금은
inode_open()을 통해 아이노드가 열릴 때 초기화됩니다.
- 이 잠금은
Click to see the refined code
/* In-memory inode. */ struct inode { struct list_elem elem; /* Element in inode list. */ block_sector_t sector; /* Sector number of disk location. */ int open_cnt; /* Number of openers. */ bool removed; /* True if deleted, false otherwise. */ int deny_write_cnt; /* 0: writes ok, >0: deny writes. */ struct inode_disk data; /* Inode content. */ struct lock inode_lock; /* Lock for synchronization */ };- 개별 아이노드 데이터에 대한 스레드 안전한 접근을 보장하기 위해
inode_open()- 이 함수는 이제 열린 아이노드 구조체 내에서
inode_lock을 초기화합니다. - 또한, 아이노드가 열릴 때
block_read_buffer_cache()를 사용하여 아이노드의 디스크 데이터를 메모리로 로드합니다.
Click to see the refined code
struct inode * inode_open (block_sector_t sector) { // other codes inode->removed = false; lock_init(&inode->inode_lock); block_read_buffer_cache (fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); return inode; }- 이 함수는 이제 열린 아이노드 구조체 내에서
inode_read_at()- 이 함수는 모든 디스크 읽기에 대해
block_read()대신block_read_buffer_cache()를 사용하도록 수정되었습니다.- 동시 접근 시 데이터 일관성을 보장하기 위해 읽기 작업 중에 아이노드의 내부 데이터를 보호하기 위해
inode_lock을 획득 및 해제합니다.
- 동시 접근 시 데이터 일관성을 보장하기 위해 읽기 작업 중에 아이노드의 내부 데이터를 보호하기 위해
Click to see the refined code
off_t inode_read_at (struct inode *inode, void *buffer_, off_t size, off_t offset) { uint8_t *buffer = buffer_; off_t bytes_read = 0; lock_acquire(&inode->inode_lock); while (size > 0) { /* Disk sector to read, starting byte offset within sector. */ block_sector_t sector_idx = byte_to_sector (inode, offset); lock_release(&inode->inode_lock); int sector_ofs = offset % BLOCK_SECTOR_SIZE; /* Bytes left in inode, bytes left in sector, lesser of the two. */ off_t inode_left = inode_length (inode) - offset; int sector_left = BLOCK_SECTOR_SIZE - sector_ofs; int min_left = inode_left < sector_left ? inode_left : sector_left; /* Number of bytes to actually copy out of this sector. */ int chunk_size = size < min_left ? size : min_left; if (chunk_size <= 0) { lock_acquire(&inode->inode_lock); break; } // read from buffer cache block_read_buffer_cache (fs_device, sector_idx, buffer, bytes_read, chunk_size, sector_ofs); /* Advance. */ size -= chunk_size; offset += chunk_size; bytes_read += chunk_size; lock_acquire(&inode->inode_lock); } lock_release(&inode->inode_lock); return bytes_read; }- 이 함수는 모든 디스크 읽기에 대해
inode_write_at()- 마찬가지로,
inode_write_at()는 모든 디스크 쓰기에 대해block_write_buffer_cache()를 사용하도록 업데이트되었습니다.- 또한,
inode_lock을 동기화를 위해 통합하여, 파일 길이가 늘어나야 할 때를 포함하여 쓰기 작업 중에 아이노드의 데이터를 보호합니다.
- 또한,
Click to see the refined code
off_t inode_write_at (struct inode *inode, const void *buffer_, off_t size, off_t offset) { const uint8_t *buffer = buffer_; off_t bytes_written = 0; if (inode->deny_write_cnt) return 0; lock_acquire(&inode->inode_lock); if(inode->data.length < offset + size) { if(!grow_file_length (&inode->data, inode->data.length, offset + size)) exit(-1); block_write_buffer_cache(fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); } while (size > 0) { /* Sector to write, starting byte offset within sector. */ block_sector_t sector_idx = byte_to_sector (inode, offset); lock_release(&inode->inode_lock); int sector_ofs = offset % BLOCK_SECTOR_SIZE; /* Bytes left in inode, bytes left in sector, lesser of the two. */ off_t inode_left = inode_length (inode) - offset; int sector_left = BLOCK_SECTOR_SIZE - sector_ofs; int min_left = inode_left < sector_left ? inode_left : sector_left; /* Number of bytes to actually write into this sector. */ int chunk_size = size < min_left ? size : min_left; if (chunk_size <= 0) { lock_acquire(&inode->inode_lock); break; } // write to buffer cache block_write_buffer_cache(fs_device, sector_idx, buffer, bytes_written, chunk_size, sector_ofs); /* Advance. */ size -= chunk_size; offset += chunk_size; bytes_written += chunk_size; lock_acquire(&inode->inode_lock); } lock_release(&inode->inode_lock); return bytes_written; }- 마찬가지로,
thread.hstruct thread- 새로운 멤버인
parent_thread_pointer가struct thread에 추가되었습니다.- 이 포인터는 자식 스레드가 부모와 관련된 정보에 접근할 수 있도록 하며, 이는 특정 시나리오에서 공유 자원 및 상속 (예: 디렉토리 정보 또는 페이지 디렉토리)에 특히 유용합니다.
Click to see the refined code
// other codes struct thread *parent_thread_pointer; /* pointer to its parent thread */ // other codes- 새로운 멤버인
thread.cinit_thread()parent_thread_pointer를 기본적으로NULL로 초기화합니다.
Click to see the refined code
static void init_thread (struct thread *t, const char *name, int priority) { // other codes t->current_clock_index = 0; list_init(&t->mmap_table); t->current_available_map_id = 0; t->parent_thread_pointer = NULL; // initializes as NULL old_level = intr_disable (); list_push_back (&all_list, &t->allelem); intr_set_level (old_level); }thread_create()- 새로운 자식 스레드가 생성될 때,
thread_create()는 새로운 스레드의parent_thread_pointer를 현재 실행 중인 스레드로 명시적으로 설정하여, 부모-자식 관계를 확립합니다.
Click to see the refined code
tid_t thread_create (const char *name, int priority, thread_func *function, void *aux) { // other codes #ifdef USERPROG /* push child process to parent */ list_push_back(&thread_current()->children, &t->childelem); #endif /* Update pointer to its parent thread */ t->parent_thread_pointer = thread_current(); /* Add to run queue. */ thread_unblock(t); if(t->priority > thread_current()->priority) thread_yield(); return tid; }- 새로운 자식 스레드가 생성될 때,
syscall.cis_valid_address()- 사용자 제공 메모리 주소의 유효성을 검사하는 이 함수가 향상되었습니다.
- 이제 현재 스레드의 페이지 디렉토리를 확인하며, 주소를 찾을 수 없는 경우 부모 스레드의 페이지 디렉토리에서 주소를 찾으려고 시도합니다.
- 이 수정은 공유 메모리 영역이나 상속된 자원이 부모의 주소 공간에 존재할 수 있는 시나리오를 처리합니다.
Click to see the refined code
bool is_valid_address(void *ptr) { if(ptr != NULL && is_user_vaddr(ptr) == true) { if(pagedir_get_page(thread_current()->pagedir, ptr) != NULL) return true; else { if(thread_current()->parent_thread_pointer != NULL && thread_current()->parent_thread_pointer->pagedir != NULL && pagedir_get_page(thread_current()->parent_thread_pointer->pagedir, ptr) != NULL) { return true; } } } return false; }- 사용자 제공 메모리 주소의 유효성을 검사하는 이 함수가 향상되었습니다.
page.chandle_page_fault()- 페이지 폴트 예외를 처리하는 이 함수는 페이지 폴트 발생 시 잠금을 올바르게 관리하도록 수정되었습니다.
- 구체적으로, 페이지 폴트가 발생할 때 현재 스레드가
buffer_cache_lock을 보유하고 있다면,- 폴트를 처리하기 전에 잠금이 일시적으로 해제되고, 처리 후에 다시 획득됩니다.
- 이는 페이지 폴트 핸들러 자체가 디스크에 접근해야 할 수 있는 경우 잠재적인 교착 상태나 재진입 문제를 방지합니다. 그렇지 않으면 재귀적인 잠금 시도로 이어질 수 있습니다.
- 구체적으로, 페이지 폴트가 발생할 때 현재 스레드가
Click to see the refined code
bool handle_page_fault(struct spt_entry *target_spt_entry) { uint8_t *kpage = palloc_get_page (PAL_USER | PAL_ZERO); bool is_lock_already_owned = lock_held_by_current_thread(&filesys_lock); if(is_lock_already_owned == false) lock_acquire(&filesys_lock); // now it handles buffer_cache_lock bool is_buffer_lock_already_owned = lock_held_by_current_thread(&buffer_cache_lock); if(is_buffer_lock_already_owned == true) lock_release(&buffer_cache_lock); // other codes // now it handles buffer_cache_lock if(is_buffer_lock_already_owned == true) lock_acquire(&buffer_cache_lock); if(is_lock_already_owned == false) lock_release(&filesys_lock); // other codes }- 페이지 폴트 예외를 처리하는 이 함수는 페이지 폴트 발생 시 잠금을 올바르게 관리하도록 수정되었습니다.
결론
- 버퍼 캐시의 성공적인 구현으로, PintOS는 이제 직접적인 디스크 접근을 최소화하여 파일 I/O 성능을 크게 향상시킵니다.
- 이 중요한 구성 요소는 데이터 전송을 최적화하고 파일 시스템 작업의 지연 시간 (latency)을 줄입니다.
- 하지만, 최종 프로젝트를 완전히 완료하기 위해 두 가지 추가 목표가 남아 있으며, 이는 다음 섹션에서 다루어집니다.
Part 2: 확장 가능한 파일 (Extensible Files)
목표
- 이 섹션의 주요 목표는 파일 시스템을 수정하여 동적 파일 크기 변경을 가능하게 하고, 파일이 필요에 따라 성장할 수 있도록 하는 것입니다.
기존 문제
- 현재 PintOS는 파일 확장성을 제한합니다.
- 원래의
struct inode_disk는 본질적으로 단일의 연속적인 데이터 블록을 가리키는start섹터만을 포함합니다. - 길이 필드가 파일 크기를 나타내지만, 이 설계는 파일이 비연속적인 디스크 블록에 걸쳐 있는 것을 본질적으로 방지합니다.
- 결과적으로, 파일이 처음에 할당된 연속적인 공간을 넘어 확장해야 하는 경우, 추가적인, 분리된 데이터 블록을 참조할 아이노드 내 메커니즘이 없기 때문에 쉽게 그렇게 할 수 없습니다.
- 원래의
-
이는 파일 증가 및 전반적인 파일 시스템 유연성을 크게 제한합니다.
Click to see the original code
struct inode_disk { block_sector_t start; /* First data sector. */ off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ uint32_t unused[125]; /* Not used. */ };
해결책
- 핵심 해결책은 계층적 블록 주소 지정 체계를 지원하도록
struct inode_disk를 근본적으로 재설계하는 것입니다. 이는 단일start포인터를 직접 및 간접 포인터의 조합으로 대체합니다.- 이 개정된 구조를 통해 파일은 디스크 전반에 걸쳐 잠재적으로 비연속적인 여러 데이터 블록을 참조하여 동적으로 확장할 수 있습니다.
- 이 변경 사항은 최대 지원 파일 크기를 약 $8 \text{ MB}$로 크게 증가시킵니다.
- 이 새로운 확장 가능한 파일 메커니즘을 파일 시스템에 통합하기 위해, 몇 가지 핵심 함수가 재구현되거나 도입되었습니다:
byte_to_sector()- 이 함수는 주어진 파일 오프셋을 해당 물리적 디스크 섹터로 올바르게 변환하도록 수정되었으며, 새로운 직접, 단일 간접, 이중 간접 블록 포인터를 탐색합니다.
inode_create()- 이 함수는 파일을 초기 생성할 때 새로운 블록 할당 전략을 활용하도록 재구현되었으며, 초기 크기에 필요한 데이터 블록이 예약되도록 보장합니다.
inode_close()- 파일이 제거될 때 아이노드와 관련된 모든 데이터 블록을 적절하게 할당 해제하도록 업데이트되었습니다.
grow_file_length()- 파일 크기를 확장해야 할 때 새로운 디스크 블록의 동적 할당을 관리하기 위해 특별히 새로운 유틸리티 함수가 도입되었습니다.
- 이 함수는 초기 할당을 위해
inode_create()에 의해, 그리고 파일을 확장하는 쓰기 작업 중에inode_write_at()에 의해 활용됩니다.
free_data_blocks()inode_disk구조체와 관련된 모든 디스크 섹터 (직접, 단일 간접, 이중 간접)를 재귀적으로 탐색하고 자유 맵 (free map)으로 반환하기 위해 새로운 함수가 생성되었습니다.
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
inode.cstruct inode_disk- 이 구조체는 새로운 블록 매핑 체계를 통합하기 위해 근본적으로 개정되었습니다.
- 이제 124개의
direct_data_block_table엔트리를 포함하며, 이는 데이터 블록을 직접 가리키는 섹터 인덱스입니다. - 추가적으로,
single_indirect_data_block_sector_index및double_indirect_data_block_sector_index를 도입합니다.- 이 간접 포인터들은 차례로 추가적인 데이터 블록 섹터 인덱스 목록을 포함하는 다른 블록들을 가리킵니다.
- 직접 엔트리 수 $124$는
inode_disk구조체에 전용된 단일 디스크 섹터 내의 나머지 공간을 최대한 활용하도록 전략적으로 선택된 숫자이며, 효율성을 극대화합니다.
- 이제 124개의
- 간접 블록의 도입은 파일 시스템이 훨씬 더 많은 수의 데이터 블록을 주소 지정할 수 있는 능력을 극적으로 확장합니다.
Click to see the refined code
#define DIRECT_BLOCK_ENTRIES 124 #define INDIRECT_BLOCK_ENTRIES (BLOCK_SECTOR_SIZE / sizeof (block_sector_t)) struct inode_disk { off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ block_sector_t direct_data_block_table [DIRECT_BLOCK_ENTRIES]; block_sector_t single_indirect_data_block_sector_index; block_sector_t double_indirect_data_block_sector_index; };- 이 구조체는 새로운 블록 매핑 체계를 통합하기 위해 근본적으로 개정되었습니다.
byte_to_sector()- 이 함수의 로직은 새로운
inode_disk구조체를 지원하도록 전면적으로 개정되었습니다.- 파일 오프셋이 주어지면, 해당 데이터 블록이 직접 포인터, 단일 간접 포인터, 또는 이중 간접 포인터를 통해 참조되는지 지능적으로 판단합니다.
- 최종 데이터 섹터를 찾기 위해 필요한 중간 인덱스 블록을 버퍼 캐시에서 읽어옵니다.
Click to see the refined code
static block_sector_t byte_to_sector (const struct inode *inode, off_t target_position) { ASSERT (inode != NULL); if (target_position >= inode->data.length) return -1; off_t block_index = target_position / BLOCK_SECTOR_SIZE; if(block_index < DIRECT_BLOCK_ENTRIES) return inode->data.direct_data_block_table[block_index]; block_index -= DIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES) { block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode->data.single_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); return indirect_table[block_index]; } block_index -= INDIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES * INDIRECT_BLOCK_ENTRIES) { block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode->data.double_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); int double_block_index = block_index/INDIRECT_BLOCK_ENTRIES; block_read_buffer_cache(fs_device, indirect_table[double_block_index], indirect_table, 0, BLOCK_SECTOR_SIZE, 0); return indirect_table[block_index - double_block_index * INDIRECT_BLOCK_ENTRIES]; } return exit(-1); }- 이 함수의 로직은 새로운
grow_file_length()- 이 핵심적인 새로운 함수는 파일 길이가 증가할 때 데이터 블록의 동적 할당을 관리합니다.
- 현재 길이와 목표 새 길이를 인수로 받습니다.
- 성장을 수용하기 위해 필요에 따라 자유 맵에서 새 섹터를 반복적으로 할당합니다.
- 이 함수는 직접 블록, 단일 간접 블록 (간접 테이블 자체 포함), 이중 간접 블록 (두 레벨의 간접 테이블 모두 포함)의 할당을 세심하게 처리하여, 새로 할당된 모든 블록이 데이터 무결성을 위해 0으로 초기화되도록 보장합니다.
- 새로 생성된 테이블은 $-1$로 초기화됩니다.
- 이 함수는 초기 할당을 위해
inode_create()에 의해 호출되며, 쓰기 작업이 파일을 확장할 때inode_write_at()에 의해 호출됩니다.
Click to see the refined code
/* Handles the extension of the file The caller of this function should write modifiied inode_disk to disk */ static bool grow_file_length (struct inode_disk *inode_disk, off_t length, off_t new_length) { static char zeros[BLOCK_SECTOR_SIZE]; if (length == new_length) return true; // if the request is to decrease the size, then block it if (length > new_length) return false; inode_disk->length = new_length; off_t number_of_blocks_allocated = 0; // align the length as BLOCK_SECTOR_SIZE // adjustment is needed to calculate the block index properly when length is 512, 1024, ... if (length > 0) number_of_blocks_allocated = (length - 1) / BLOCK_SECTOR_SIZE + 1; off_t number_of_blocks_to_allocate = (new_length - 1) / BLOCK_SECTOR_SIZE + 1; block_sector_t double_indirect_table[INDIRECT_BLOCK_ENTRIES], single_indirect_table[INDIRECT_BLOCK_ENTRIES]; block_sector_t sector; off_t block_index; for (off_t cur_allocated_blocks = number_of_blocks_allocated; cur_allocated_blocks < number_of_blocks_to_allocate; ++cur_allocated_blocks) { sector = 0; block_index = cur_allocated_blocks; if(block_index < DIRECT_BLOCK_ENTRIES) { // case for direct if(inode_disk->direct_data_block_table[block_index] == (block_sector_t) -1) { // if current block index is not allocated, allocate new sector if (!free_map_allocate (1, §or)) return false; inode_disk->direct_data_block_table[block_index] = sector; } // if the sector has been already allocated, then it's good to go } else { // case for indirect block_index -= DIRECT_BLOCK_ENTRIES; if(block_index < INDIRECT_BLOCK_ENTRIES) { // case for single-indirect if (inode_disk->single_indirect_data_block_sector_index == (block_sector_t) -1) { // if the single-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &inode_disk->single_indirect_data_block_sector_index)) return false; memset (single_indirect_table, -1, BLOCK_SECTOR_SIZE); } else { // if the indirect table exists, then load it block_read_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } // if current block index is not allocated, allocate new sector if(single_indirect_table[block_index] == (block_sector_t) -1) { if (!free_map_allocate (1, §or)) return false; single_indirect_table[block_index] = sector; // update the block which contains single-indirect table block_write_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } } else { // case for double-indirect block_index -= INDIRECT_BLOCK_ENTRIES; if (inode_disk->double_indirect_data_block_sector_index == (block_sector_t) -1) { // if the double-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &inode_disk->double_indirect_data_block_sector_index)) return false; memset (double_indirect_table, -1, BLOCK_SECTOR_SIZE); } else { // if the double-indirect table exists, then load it block_read_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } int double_block_index = block_index/INDIRECT_BLOCK_ENTRIES; if (double_indirect_table[double_block_index] == (block_sector_t) -1) { // if the single-indirect table is not allocated, then allocate new one if (!free_map_allocate (1, &double_indirect_table[double_block_index])) return false; // update double-indirect table block_write_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); memset (single_indirect_table, -1, BLOCK_SECTOR_SIZE); // update single-indirect table block_write_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } else { // if single-indirect table exists, then load it block_read_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } // if current block index is not allocated, allocate new sector if(single_indirect_table[block_index - double_block_index*INDIRECT_BLOCK_ENTRIES] == (block_sector_t) -1) { if (!free_map_allocate (1, §or)) return false; single_indirect_table[block_index - double_block_index*INDIRECT_BLOCK_ENTRIES] = sector; // update the block which contains single-indirect table block_write_buffer_cache(fs_device, double_indirect_table[double_block_index], single_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); } } } // initialize the new sector as zeros block_write_buffer_cache(fs_device, sector, zeros, 0, BLOCK_SECTOR_SIZE, 0); } return true; }- 이 핵심적인 새로운 함수는 파일 길이가 증가할 때 데이터 블록의 동적 할당을 관리합니다.
inode_create()- 이 함수는 새로 생성되는 파일의 지정된 길이를 기반으로 초기 데이터 블록을 할당하기 위해
grow_file_length()를 활용하도록 재구현되었습니다. grow_file_length()가 필요한 블록 할당을 성공적으로 완료하고inode_disk구조체를 업데이트한 후,inode_create()는 이 업데이트된inode_disk를 버퍼 캐시를 사용하여 디스크의 지정된 섹터에 기록합니다.
Click to see the refined code
bool inode_create (block_sector_t sector, off_t length) { struct inode_disk *disk_inode = NULL; bool success = false; ASSERT (length >= 0); /* If this assertion fails, the inode structure is not exactly one sector in size, and you should fix that. */ ASSERT (sizeof *disk_inode == BLOCK_SECTOR_SIZE); disk_inode = calloc (1, sizeof *disk_inode); if (disk_inode != NULL) { // initialize disk_inode as -1, leading to the maximum number of block_sector_t because it is unsigned type memset (disk_inode, -1, BLOCK_SECTOR_SIZE); disk_inode->length = 0; if (!grow_file_length(disk_inode, disk_inode->length, length)) { free(disk_inode); return false; } disk_inode->magic = INODE_MAGIC; block_write(fs_device, sector, disk_inode); free (disk_inode); success = true; } return success; }- 이 함수는 새로 생성되는 파일의 지정된 길이를 기반으로 초기 데이터 블록을 할당하기 위해
inode_write_at()- 이 함수는 쓰기 작업 중에 파일 성장을 지원하도록 수정되었습니다.
- 데이터를 쓰기 전에, 쓰기가 현재
inode->data.length를 넘어 확장되는지 확인합니다.- 확장이 필요한 경우,
grow_file_length()를 호출하여 새로운 데이터 블록을 동적으로 할당한 후, 실제 데이터를 버퍼 캐시에 쓰는 작업을 진행합니다.
- 확장이 필요한 경우,
Click to see the refined code
// other codes if (inode->deny_write_cnt) return 0; lock_acquire(&buffer_cache_lock); if(inode->data.length < offset + size) { lock_release(&buffer_cache_lock); if(!grow_file_length (&inode->data, inode->data.length, offset + size)) exit(-1); lock_acquire(&buffer_cache_lock); block_write_buffer_cache(fs_device, inode->sector, &inode->data, 0, BLOCK_SECTOR_SIZE, 0); } while (size > 0) // other codesfree_data_blocks()- 이 새로운 함수는 주어진
inode_disk구조체에 속하는 모든 디스크 섹터를 할당 해제하는 역할을 합니다. - 이는 직접 데이터 블록 엔트리를 체계적으로 순회하며, 할당된 모든 섹터를 해제합니다.
- 그런 다음, 단일 간접 포인터가 가리키는 섹터를 할당 해제하는 작업을 진행하고,
- 마지막으로, 이중 간접 포인터에 의해 참조되는 블록들, 그리고 간접 테이블 자체까지 포함하여 재귀적으로 할당 해제하며, 해제된 모든 섹터를 자유 맵 (free map)으로 반환합니다.
Click to see the refined code
void free_data_blocks (struct inode_disk *inode_disk) { int current_count; for (current_count = 0; current_count < DIRECT_BLOCK_ENTRIES; ++current_count) { if (inode_disk->direct_data_block_table[current_count] == (block_sector_t) -1) break; free_map_release(inode_disk->direct_data_block_table[current_count], 1); } if (inode_disk->single_indirect_data_block_sector_index == (block_sector_t) -1) return; block_sector_t indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode_disk->single_indirect_data_block_sector_index, indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (indirect_table[current_count] == (block_sector_t) -1) break; free_map_release(indirect_table[current_count], 1); } free_map_release(inode_disk->single_indirect_data_block_sector_index, 1); if (inode_disk->double_indirect_data_block_sector_index == (block_sector_t) -1) return; block_sector_t double_indirect_table[INDIRECT_BLOCK_ENTRIES]; block_read_buffer_cache(fs_device, inode_disk->double_indirect_data_block_sector_index, double_indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (double_indirect_table[current_count] == (block_sector_t) -1) break; block_read_buffer_cache(fs_device, double_indirect_table[current_count], indirect_table, 0, BLOCK_SECTOR_SIZE, 0); for (current_count = 0; current_count < INDIRECT_BLOCK_ENTRIES; ++current_count) { if (indirect_table[current_count] == (block_sector_t) -1) break; free_map_release(indirect_table[current_count], 1); } free_map_release(double_indirect_table[current_count], 1); } free_map_release(inode_disk->double_indirect_data_block_sector_index, 1); }- 이 새로운 함수는 주어진
inode_close()- 이 함수는 적절한 자원 관리를 보장하도록 재구현되었습니다.
- 아이노드가 닫히고 제거를 위해 표시되면 (
inode->removed == true), 이제free_data_blocks()를 호출하여 관련된 모든 데이터 섹터를 할당 해제합니다.
- 아이노드가 닫히고 제거를 위해 표시되면 (
Click to see the refined code
void inode_close (struct inode *inode) { /* Ignore null pointer. */ if (inode == NULL) return; /* Release resources if this was the last opener. */ if (--inode->open_cnt == 0) { /* Remove from inode list and release lock. */ list_remove (&inode->elem); /* Deallocate blocks if removed. */ if (inode->removed) { free_data_blocks(&inode->data); free_map_release(inode->sector, 1); } free (inode); } }- 이 함수는 적절한 자원 관리를 보장하도록 재구현되었습니다.
결론
- 이러한 개선 덕분에, PintOS 파일은 이제 동적으로 성장할 수 있으며, 최대 약 $8.123 \text{ MB}$의 파일 크기를 지원합니다.
- 이는 파일 시스템의 유연성과 유용성을 크게 향상시킵니다.
- 이제 버퍼 캐시와 확장 가능한 파일이 모두 구현되었으므로, 하나의 주요 작업만 남았습니다:
- 서브 디렉토리 도입. 이는 다음 섹션의 초점입니다.
Part 3: 서브 디렉토리 (Subdirectories)
목표
- 이 최종 부분의 목표는 계층적 디렉토리 구조를 구현하여, PintOS 파일 시스템 내에서 서브 디렉토리의 생성 및 관리를 가능하게 하는 것입니다.
기존 문제
- 현재 PintOS는 계층적 디렉토리에 대한 지원이 부족합니다.
- 이러한 한계는 디렉토리와 일반 파일을 구별하거나 다단계 디렉토리 트리를 탐색하기 위한 전용 시스템 호출 또는 기반 파일 시스템 메커니즘의 부재에서 비롯됩니다.
- 기존 파일 시스템은 단일 구조 (flat structure)를 가정하고 있어, 파일을 서브 디렉토리로 구성하는 것이 불가능합니다.
Click to see the original code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { case SYS_HALT: halt(); break; case SYS_EXIT: exit(current_esp[1]); break; case SYS_EXEC: f->eax = exec(current_esp[1]); break; case SYS_WAIT: f->eax = wait(current_esp[1]); break; case SYS_CREATE: f->eax = create(current_esp[1], current_esp[2]); break; case SYS_REMOVE: f->eax = remove(current_esp[1]); break; case SYS_OPEN: f->eax = open(current_esp[1]); break; case SYS_FILESIZE: f->eax = filesize(current_esp[1]); break; case SYS_READ: f->eax = read(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_WRITE: f->eax = write(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_SEEK: seek(current_esp[1], current_esp[2]); break; case SYS_TELL: f->eax = tell(current_esp[1]); break; case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; case SYS_CHDIR: /* missing! */ break; case SYS_MKDIR: /* missing! */ break; case SYS_READDIR: /* missing! */ break; case SYS_ISDIR: /* missing! */ break; case SYS_INUMBER: /* missing! */ break; default: PANIC("Invalid System Call"); } }
해결책
- 이 해결책은 파일 시스템을 계층적 구조로 변환하여, 서브 디렉토리의 생성, 탐색 및 관리를 가능하게 합니다.
- 이는 다음을 포함합니다:
- 파일 유형 구별
- 디스크 상의 아이노드 구조체 (
struct inode_disk)가 수정되어 아이노드가 디렉토리를 나타내는지 일반 파일을 나타내는지를 식별하는 특정 플래그가 포함됩니다. - 이를 통해 파일 시스템은 근본적인 수준에서 이들을 구별할 수 있습니다.
- 디스크 상의 아이노드 구조체 (
- 스레드별 현재 디렉토리
- 각 스레드는 이제 자체 현재 작업 디렉토리 (
.)를 유지합니다. - 이 설계는 스레드가 특정 디렉토리 컨텍스트 내에서 작동할 수 있도록 하여 상대 경로 확인을 지원합니다.
- 자식 스레드는 부모의 현재 디렉토리를 상속받아 일관된 계층적 컨텍스트를 보장합니다.
- 각 스레드는 이제 자체 현재 작업 디렉토리 (
- 새로운 디렉토리 시스템 호출
- 디렉토리 관리를 위한 필수 시스템 호출, 즉
chdir,mkdir,readdir,isdir,inumber가 구현됩니다. - 이러한 시스템 호출은 사용자 프로그램이 새로운 디렉토리 구조와 상호 작용하는 데 필요한 인터페이스를 제공합니다.
- 디렉토리 관리를 위한 필수 시스템 호출, 즉
- 경로 구문 분석 로직
- 계층적 파일 시스템 내에서 절대 경로 및 상대 경로를 확인하는 복잡성을 처리하기 위해
parse_path()라는 새로운 함수가 도입됩니다. - 이 함수는 경로를 포함하는 모든 파일 시스템 작업에 매우 중요합니다.
- 계층적 파일 시스템 내에서 절대 경로 및 상대 경로를 확인하는 복잡성을 처리하기 위해
- 파일 유형 구별
- 이러한 변경 사항을 달성하기 위해 구현은 핵심 파일 시스템 구성 요소에 대한 수정이 필요하며,
- 여기에는
inode_disk구조체가 포함되며,inode.c,filesys.c,directory.c,syscall.c의 다양한 함수에 대한 개선도 포함됩니다.
- 여기에는
구현 세부 사항
- 다음 구성 요소들이 수정되거나 도입되었습니다:
thread.hstruct threadstruct dir *타입의 새로운 데이터 멤버인current_directory가 각 스레드의 구조체에 추가되었습니다.- 이 포인터는 스레드의 현재 작업 디렉토리를 추적하여, 상대 경로 작업을 가능하게 합니다.
Click to see the refined code
// other codes struct dir *current_directory; // other codes
thread.cinit_thread()- 새로운 스레드의
current_directory멤버는NULL로 초기화됩니다.
Click to see the refined code
// other codes list_init(&t->mmap_table); t->current_available_map_id = 0; t->current_directory = NULL; // new code t->parent_thread_pointer = NULL; old_level = intr_disable (); // other codes- 새로운 스레드의
thread_create()- 새 스레드가 생성될 때, 이제 부모 스레드의
current_directory를 명시적으로 상속받습니다. - 이는
dir_reopen()을 사용하여 부모의 디렉터리를 다시 여는 방식으로 구현되었습니다.
Click to see the refined code
// other codes #ifdef USERPROG /* push child process to parent */ list_push_back(&thread_current()->children, &t->childelem); #endif /* Make the child thread inherit the current directory from its parent thread */ if (thread_current()->current_directory) t->current_directory = dir_reopen(thread_current()->current_directory); /* Update pointer to its parent thread */ t->parent_thread_pointer = thread_current(); /* Add to run queue. */ thread_unblock(t); // other codes- 새 스레드가 생성될 때, 이제 부모 스레드의
inode.cstruct inode_disk- 이 구조체는
is_directory플래그를 포함하도록 업데이트되었습니다.- 정렬(alignment)을 위해
block_sector_t타입으로 정의된 이 플래그는 해당 inode가 디렉터리를 나타내는지 여부를 명시적으로 표시합니다.
- 정렬(alignment)을 위해
- 이에 따라 섹터 크기 내에서 새 플래그를 수용하기 위해 직접 데이터 블록 엔트리 수(
DIRECT_BLOCK_ENTRIES)가 조정되었습니다.
Click to see the refined code
#define DIRECT_BLOCK_ENTRIES 123 /* now it's 123! */ struct inode_disk { off_t length; /* File size in bytes. */ unsigned magic; /* Magic number. */ block_sector_t is_directory; /* new member! */ block_sector_t direct_data_block_table [DIRECT_BLOCK_ENTRIES]; block_sector_t single_indirect_data_block_sector_index; block_sector_t double_indirect_data_block_sector_index; };- 이 구조체는
inode_create()- 이 함수는 추가적인 불리언 매개변수
is_directory_given을 받도록 수정되었습니다.- 이 매개변수는 새로 생성되는 inode가 일반 파일인지 디렉터리인지 결정하며, 이에 따라
is_directory플래그를 설정합니다.
- 이 매개변수는 새로 생성되는 inode가 일반 파일인지 디렉터리인지 결정하며, 이에 따라
- 이 변경으로 인해
inode_create()을 호출하는 모든 함수를 업데이트해야 합니다.- 구체적으로,
filesys_create(),dir_create(), 그리고free_map_create()함수가 수정 대상입니다.
Click to see the refined code
bool inode_create (block_sector_t sector, off_t length, bool is_directory_given) { // same codes disk_inode->magic = INODE_MAGIC; disk_inode->is_directory = is_directory_given; // new code block_write(fs_device, sector, disk_inode); // same codes } - 구체적으로,
- 이 함수는 추가적인 불리언 매개변수
is_inode_valid_directory()- 주어진 inode가 유효하고 존재하는 디렉터리인지(즉, 제거되지 않았으며
is_directory플래그가 설정되어 있는지)를 효율적으로 확인하기 위해 새로운 도우미 함수가 도입되었습니다.
Click to see the refined code
bool is_inode_valid_directory(const struct inode *inode) { return inode->removed == false && inode->data.is_directory == true; }- 주어진 inode가 유효하고 존재하는 디렉터리인지(즉, 제거되지 않았으며
inode.h수정된 선언부inode_create()함수의 선언이 새로운 매개변수is_directory_given을 반영하도록 업데이트되었습니다.- 새롭게 추가된
is_inode_valid_directory()함수의 선언도 포함되었습니다.
Click to see the refined code
// other codes off_t inode_length (const struct inode *); bool inode_create (block_sector_t, off_t, bool); // modified! bool is_inode_valid_directory(const struct inode *inode); // new one!
filesys.cfilesys_init()- 파일 시스템 초기화 과정에서, 이제 메인 스레드의
current_directory를 루트 디렉터리(root directory)로 설정합니다.- 이를 위해
thread.h가 포함되었습니다.
- 이를 위해
Click to see the refined code
#include "threads/thread.h" // other codes void filesys_init (bool format) { // other codes free_map_open(); // Initialize current directory of main thread struct dir *root_dir = dir_open_root(); thread_current()->current_directory = root_dir; dir_add (root_dir, ".", ROOT_DIR_SECTOR); }- 파일 시스템 초기화 과정에서, 이제 메인 스레드의
parse_path()- 이 핵심적인 새 함수는
original_path와file_name버퍼를 인자로 받습니다. - 루트 디렉터리 또는 현재 스레드의 디렉터리에서 시작하여 디렉터리 트리를 순회하며 경로 구성 요소를 해석합니다.
- 최종적으로 대상 디렉터리에 대한 포인터를 반환하고, 마지막 파일 또는 디렉터리 이름을 추출합니다.
- 경로 구성 요소가 유효하지 않거나 디렉터리가 아닌 inode를 참조하는 경우도 처리합니다.
- 경로 버퍼 크기 관리를 위해
PATH_MAX_LENGTH가filesys.h에 정의되었습니다.Click to see the refined code
struct dir * parse_path (const char *original_path, char *file_name) { struct dir *dir = NULL; if (!original_path || !file_name) return NULL; if (strlen(original_path) == 0) return NULL; char path[PATH_MAX_LENGTH + 1]; strlcpy(path, original_path, PATH_MAX_LENGTH); if (path[0] == '/') dir = dir_open_root (); else dir = dir_reopen(thread_current()->current_directory); if(is_inode_valid_directory(dir_get_inode(dir)) == false) return NULL; char *token, *next_token, *save_ptr; token = strtok_r(path, "/", &save_ptr); next_token = strtok_r(NULL, "/", &save_ptr); if(token == NULL) { strlcpy(file_name, ".", PATH_MAX_LENGTH); return dir; } while(token && next_token) { struct inode *inode = NULL; if(!dir_lookup (dir, token, &inode)) { dir_close(dir); return NULL; } if (is_inode_valid_directory(inode) == false) { dir_close(dir); return NULL; } dir_close(dir); dir = dir_open(inode); token = next_token; next_token = strtok_r(NULL, "/", &save_ptr); } strlcpy(file_name, token, PATH_MAX_LENGTH); return dir; }
- 이 핵심적인 새 함수는
filesys_create()- 이 함수는
inode_create()를 호출할 때is_directory_given플래그에false를 전달하도록 업데이트되었습니다.- 이를 통해 디스크 상에서 해당 inode가 일반 파일로 올바르게 표시되도록 보장합니다.
Click to see the refined code
bool filesys_create (const char *path, off_t initial_size) { block_sector_t inode_sector = 0; char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = (dir != NULL && free_map_allocate (1, &inode_sector) && inode_create (inode_sector, initial_size, false) && dir_add (dir, name, inode_sector)); if (!success && inode_sector != 0) free_map_release (inode_sector, 1); dir_close (dir); return success; }- 이 함수는
filesys_create_dir()- 디렉터리 생성을 담당하는 새로운 함수입니다.
parse_path()를 사용하여 부모 디렉터리를 찾은 후,dir_create()와dir_add()를 호출하여 새 디렉터리의 inode를 할당하고 등록합니다.- 새 디렉터리 내부에 특수 항목인
.(현재 디렉터리)와..(부모 디렉터리) 항목을 초기화합니다.
Click to see the refined code
/* Creates a directory */ bool filesys_create_dir(const char *path) { block_sector_t inode_sector = 0; char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = (dir != NULL && free_map_allocate (1, &inode_sector) && dir_create (inode_sector, 16) && dir_add (dir, name, inode_sector)); if(!success && inode_sector != 0) free_map_release (inode_sector, 1); if(success) { struct dir *new_dir = dir_open(inode_open(inode_sector)); dir_add (new_dir, ".", inode_sector); dir_add (new_dir, "..", inode_get_inumber(dir_get_inode(dir))); dir_close (new_dir); } dir_close (dir); return success; }- 새 디렉터리 내부에 특수 항목인
filesys_open()- 이 함수는 주어진 경로에 해당하는 inode를 찾기 위해
parse_path()를 사용하도록 수정되었습니다.
Click to see the refined code
struct file * filesys_open(const char *path) { char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); struct inode *inode = NULL; if(dir != NULL) dir_lookup(dir, name, &inode); dir_close(dir); return file_open(inode); }- 이 함수는 주어진 경로에 해당하는 inode를 찾기 위해
filesys_remove()- 이 함수는 대상 항목을 찾기 위해
parse_path()를 사용하도록 업데이트되었습니다. - 비어 있지 않은 디렉터리의 삭제를 방지하는 로직이 포함되었습니다.
- 오직
.와..만 포함된 빈 디렉터리에 대해서만 삭제가 허용됩니다.
Click to see the refined code
bool filesys_remove (const char *path) { char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); bool success = false; if(dir != NULL) { struct inode *target_inode = NULL; if(dir_lookup(dir, name, &target_inode) == false) return false; if(is_inode_valid_directory(target_inode) == false) { inode_close(target_inode); success = dir_remove(dir, name); } else { char temp_name[PATH_MAX_LENGTH + 1]; struct dir *dir_to_check = dir_open(target_inode); char previous_name[PATH_MAX_LENGTH + 1]; for(int i = 0; i < 3; ++i) { dir_readdir(dir_to_check, temp_name); if(strcmp(temp_name, "..") == 0 && strcmp(previous_name, temp_name) == 0) { success = true; break; } strlcpy(previous_name, temp_name, sizeof(previous_name)); } dir_close(dir_to_check); // remove directory only it's empty if(success) success = dir_remove(dir, name); } } dir_close(dir); return success; } - 오직
- 이 함수는 대상 항목을 찾기 위해
filesys.h- 신규 선언 및 상수
parse_path()및filesys_create_dir()함수 선언이 추가되었습니다.- 파일 경로의 최대 길이를 지정하기 위해
PATH_MAX_LENGTH가128로 정의되었습니다.
Click to see the refined code
#define PATH_MAX_LENGTH 128 // other codes struct dir *parse_path(const char *original_path, char *file_name); bool filesys_create_dir(const char *path);
- 신규 선언 및 상수
directory.cdir_create()- 이 함수는
inode_create()를 호출할 때is_directory_given플래그에true를 전달하도록 수정되었습니다.- 이를 통해 새로 생성되는 디렉터리 inode가 올바르게 디렉터리로 식별되도록 보장합니다.
Click to see the refined code
bool dir_create (block_sector_t sector, size_t entry_cnt) { return inode_create (sector, entry_cnt * sizeof (struct dir_entry), true); }- 이 함수는
directory.hNAME_MAX- 파일 이름의 최대 길이(
NAME_MAX)가 기존 값에서 26자로 증가되었습니다.- 이 조정을 통해 각 디스크 블록이 정확히 16개의 디렉터리 엔트리를 수용할 수 있게 되어 디렉터리 내용 저장의 저장 효율성이 최적화되었습니다.
Click to see the refined code
#define NAME_MAX 26- 파일 이름의 최대 길이(
free-map.cfree_map_create()- 이 함수는 프리 맵(free map) inode를 생성할 때
inode_create()에is_directory_given플래그로false를 전달하도록 업데이트되었습니다.- 이를 통해 프리 맵 inode가 디렉터리가 아닌 일반 파일로 올바르게 표시됩니다.
Click to see the refined code
void free_map_create (void) { /* Create inode. */ if (!inode_create (FREE_MAP_SECTOR, bitmap_file_size (free_map), false)) // modified PANIC ("free map creation failed"); // other codes }- 이 함수는 프리 맵(free map) inode를 생성할 때
syscall.c- 헤더 포함 변경
- 기존의
vaddr.h대신filesys.h를 포함하도록 변경되었습니다.- 이를 통해 새롭게 정의된 파일 시스템 인터페이스와 구조체들에 접근할 수 있게 되었습니다.
Click to see the refined code
#include "vm/page.h" #include "filesys/filesys.h" //#include "threads/vaddr.h" // other codes - 기존의
chdir()- 호출 프로세스의 현재 작업 디렉터리(current working directory)를 변경하는 새로운 시스템 호출입니다.
parse_path()를 사용하여 새 디렉터리를 해석하고, 성공 시 해당 스레드의current_directory포인터를 업데이트합니다.Click to see the refined code
bool chdir(const char *path_original) { char path[PATH_MAX_LENGTH + 1]; strlcpy(path, path_original, PATH_MAX_LENGTH); strlcat(path, "/0", PATH_MAX_LENGTH); char name[PATH_MAX_LENGTH + 1]; struct dir *dir = parse_path(path, name); if(!dir) return false; dir_close(thread_current()->current_directory); thread_current()->current_directory = dir; return true; }
mkdir()- 지정된 경로에 새 디렉터리를 생성하는 새로운 시스템 호출입니다.
- 내부적으로
filesys_create_dir()를 호출하여 디렉터리 생성을 수행합니다.Click to see the refined code
bool mkdir(const char *dir) { return filesys_create_dir(dir); }
readdir()- 디렉터리를 나타내는 파일 디스크립터로부터 디렉터리 엔트리를 읽어오는 새로운 시스템 호출입니다.
- 디렉터리를 순회하면서 각 엔트리의 이름을 반환합니다.
- 더 이상 읽을 엔트리가 없는 경우
false를 반환합니다.
- 더 이상 읽을 엔트리가 없는 경우
- 무한 루프 또는 불필요한 노출을 방지하기 위해 특수 엔트리인
.와..는 명시적으로 필터링됩니다.
Click to see the refined code
bool readdir(int fd, char *name) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); struct inode *target_inode = file_get_inode(target_file); if(target_inode == NULL || is_inode_valid_directory(target_inode) == false) return false; struct dir *dir = dir_open(target_inode); if(dir == NULL) return false; bool was_parent_previously = false; if(strcmp(name, "..") == 0) was_parent_previously = true; int current_count; bool result = true; off_t *pos = (off_t *)target_file + 1; for(current_count = 0; current_count <= *pos && result; ++current_count) result = dir_readdir(dir, name); if(current_count <= *pos == false) ++(*pos); if(was_parent_previously && strcmp(name, "..") == 0) return false; if(strcmp(name, ".") == 0 || strcmp(name, "..") == 0) return readdir(fd, name); return result; } - 디렉터리를 순회하면서 각 엔트리의 이름을 반환합니다.
- 디렉터리를 나타내는 파일 디스크립터로부터 디렉터리 엔트리를 읽어오는 새로운 시스템 호출입니다.
isdir()- 주어진 파일 디스크립터가 디렉터리를 가리키는지 확인하는 새로운 시스템 호출입니다.
- 내부적으로
is_inode_valid_directory()를 사용하여 해당 inode가 유효한 디렉터리인지 판별합니다.Click to see the refined code
bool isdir(int fd) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); return is_inode_valid_directory(file_get_inode(target_file)); }
inumber()- 주어진 파일 디스크립터에 연결된 inode 번호(섹터 인덱스)를 반환하는 새로운 시스템 호출입니다.
Click to see the refined code
block_sector_t inumber(int fd) { struct file *target_file = thread_current()->fd_table[fd]; if(target_file == NULL) exit(-1); return inode_get_inumber(file_get_inode(target_file)); }write()write()시스템 호출은 디렉터리 파일 디스크립터에 대한 쓰기 작업을 금지하도록 업데이트되었습니다.- 디렉터리에 쓰기를 시도할 경우
exit(-1)을 호출합니다.
Click to see the refined code
// other codes if(fd < 0 || fd >= FD_TABLE_MAX_SLOT || thread_current()->fd_table[fd] == NULL || is_inode_valid_directory(file_get_inode(thread_current()->fd_table[fd]))) // new condition! { exit(-1); } lock_acquire(&filesys_lock); // other codes- 디렉터리에 쓰기를 시도할 경우
syscall_handler()- 메인 시스템 호출 핸들러는 새롭게 구현된 디렉터리 관련 시스템 호출들(
SYS_CHDIR,SYS_MKDIR,SYS_READDIR,SYS_ISDIR,SYS_INUMBER)을 해당 구현 함수로 디스패치하도록 수정되었습니다.
Click to see the refined code
static void syscall_handler(struct intr_frame* f) { int *current_esp = f->esp; if(is_valid_address(current_esp) == false) return; switch (current_esp[0]) { case SYS_HALT: halt(); break; case SYS_EXIT: exit(current_esp[1]); break; case SYS_EXEC: f->eax = exec(current_esp[1]); break; case SYS_WAIT: f->eax = wait(current_esp[1]); break; case SYS_CREATE: f->eax = create(current_esp[1], current_esp[2]); break; case SYS_REMOVE: f->eax = remove(current_esp[1]); break; case SYS_OPEN: f->eax = open(current_esp[1]); break; case SYS_FILESIZE: f->eax = filesize(current_esp[1]); break; case SYS_READ: f->eax = read(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_WRITE: f->eax = write(current_esp[1], current_esp[2], current_esp[3]); break; case SYS_SEEK: seek(current_esp[1], current_esp[2]); break; case SYS_TELL: f->eax = tell(current_esp[1]); break; case SYS_CLOSE: close(current_esp[1]); break; case SYS_MMAP: f->eax = mmap(current_esp[1], current_esp[2]); break; case SYS_MUNMAP: munmap(current_esp[1]); break; case SYS_CHDIR: f->eax = chdir(current_esp[1]); break; case SYS_MKDIR: f->eax = mkdir(current_esp[1]); break; case SYS_READDIR: f->eax = readdir(current_esp[1], current_esp[2]); break; case SYS_ISDIR: f->eax = isdir(current_esp[1]); break; case SYS_INUMBER: f->eax = inumber(current_esp[1]); break; default: PANIC("Invalid System Call"); } }- 메인 시스템 호출 핸들러는 새롭게 구현된 디렉터리 관련 시스템 호출들(
- 헤더 포함 변경
결론
- 하위 디렉터리 구현을 통해 PintOS는 이제 완전한 계층적 파일 시스템(hierarchical file system)을 지원하며, 본 최종 프로젝트의 모든 목표를 충족하였습니다.
- 이를 통해 견고하고 기능적인 파일 시스템이 완성되어, 유연한 데이터 조직 및 관리가 가능해졌습니다.
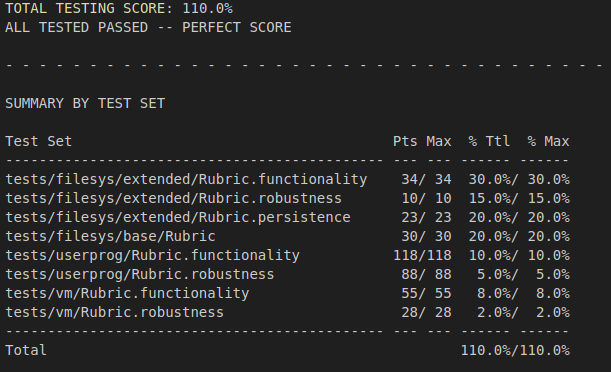
향상된 점수
최종 의견
- 본 프로젝트는 기본적인 PintOS 파일 시스템을 보다 견고하고 효율적이며 사용자 친화적인 구성 요소로 크게 향상시켰습니다.
- 버퍼 캐시(buffer cache) 도입을 통해 지능적인 데이터 캐싱으로 I/O 성능을 획기적으로 개선하였으며, 파일 구조를 재설계하여 확장 가능 파일(extensible files)을 지원함으로써 파일이 훨씬 더 큰 크기로 동적으로 성장할 수 있도록 하였습니다.
- 마지막으로 하위 디렉터리(subdirectories) 구현을 통해 계층적이고 직관적인 파일 구성이 가능해져 사용자 경험을 크게 향상시켰을 뿐만 아니라, 향후 고급 기능 확장의 기반을 마련하였습니다.
- 이러한 일련의 개선은 핵심 파일 시스템 메커니즘에 대한 깊은 이해와 정교한 운영체제 구성 요소 개발 과정에 대한 통찰을 보여줍니다.
깃허브 저장소
- PintOS를 위해 수정한 실제 파일들은 다음 깃허브 저장소에서 확인할 수 있습니다: PintOS
Leave a comment